데이터베이스란
- 데이터베이스는 조직화/구조화된 데이터 모음이다.
- 여러 사용자/프로그램에 의해 공동(Shared)으로 사용될 정보를 통합(Integrated)(중복을 배제 혹은 최소화)하여, 언제든지 접근할 수 있도록 저장장치에 저장(Stored)한, 필수적인 운영(Operational) 데이터를 말한다.
-
데이터베이스 이전에는 파일 시스템을 이용하여 데이터를 관리했다. 하지만 파일 시스템에서는 독립된 파일 단위로 데이터를 저장했기 때문에, 데이터의 종속성*과 중복성이 발생한다는 문제가 있었고, 이는 결국 데이터의 무결성(Integrity)을 위배하는 문제를 일으켰다. 이를 해결하기 위해 도입된 시스템이 데이터베이스 시스템이다.
- 데이터 종속성 : 데이터와 응용프로그램 사이 의존관계가 있는 것. 데이터의 구성이나 접근방법이 변경될 때 응용프로그램의 구조도 함께 변경해야하는 불편함이 있다.
- 데이터 중복성 : 같은 데이터가 여러 파일에 중복되어 저장되고 관리되는 것. 한 데이터가 수정되면 중복된 모든 데이터를 수정해야하는 불편함이 있다.
데이터베이스의 특징
- 실시간 접근성 : 쿼리를 실시간으로 처리/응답한다.
- 계속적인 변화 : 데이터 값이 삽입, 삭제, 수정 등에 의해 계속 변화한다.
- 동시 공유 : 여러 사용자에게 공유된다.
- 내용에 따른 참조 : 데이터의 물리적 위치가 아닌 데이터 값으로 참조된다.
- 데이터 중복의 최소화 : 동일 데이터의 중복을 최소화한다.
데이터베이스 시스템
데이터베이스를 이용해 자료를 저장/관리/접근하는 데 필요한 시스템을 가리킨다. 데이터베이스, 데이터베이스 관리시스템(DBMS), 그리고 데이터모델로 구성돼 있다.
- 데이터베이스는 하드디스크에 물리적으로 저장된 데이터이다.
- DBMS는 주기억장치에 상주해 사용자와 데이터베이스를 연결시켜주는 소프트웨어이다.
-
데이터 모델은 논리적인 개념으로, 데이터의 저장 형태에 관한 내용이다.
⇒ 스키마(schema)는 특정 데이터베이스의 구조 등을 정의한 메타데이터이며, 인스턴스(instance)는 스키마를 만족하는 실제 데이터의 집합이다.
그 외에도, 데이터베이스 언어와 사용자에 대한 이해도 필요하다.
- 데이터베이스 전용 언어는 SQL이다.
- 데이터베이스 사용자는 일반 사용자, 응용 프로그래머, SQL 사용자, 데이터베이스 관리자(DBA)로 구분할 수 있다.
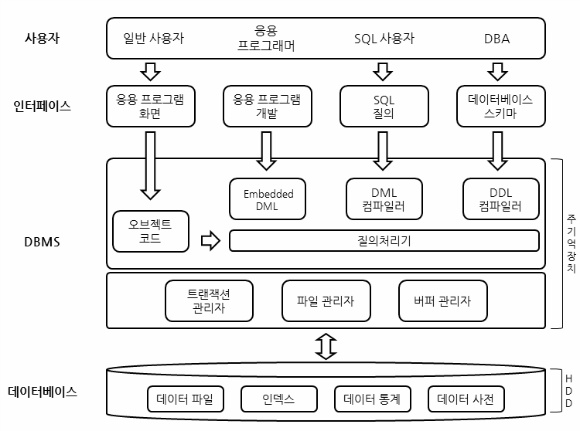
DBMS
DBMS(DataBase Management System)는 위에서 말했듯 파일 시스템의 문제를 해결하기 위해 등장했다. 사용자와 DB 사이에서 사용자의 요구에 따라 데이터베이스의 내용을 정의, 조작, 제어할 수 있도록 하며, 이를 통해 다수의 사용자/응용프로그램이 DB를 공유할 수 있도록 관리하는 소프트웨어이다.
DBMS의 필수 기능
-
정의 — DB에 저장될 데이터의 Type과 구조, 제약 조건 등 명시
ex) 다음 SQL 명령어들(Data Definition Language, DDL):
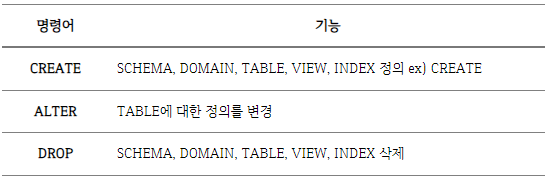
-
조작 — 검색, 갱신, 삽입, 삭제 등을 위한 인터페이스 제공
ex) 다음 SQL 명령어들(Data Manipulation Language, DML):
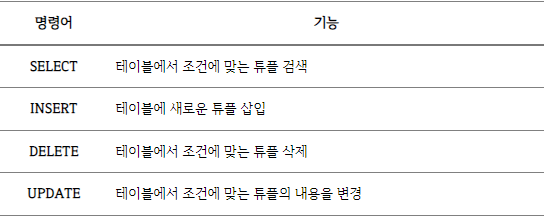
-
제어 — 무결성 유지, 데이터 보안, 병행 제어 등 관리 목적.
ex) 다음 SQL 명령어들(Data Control Language, DCL):
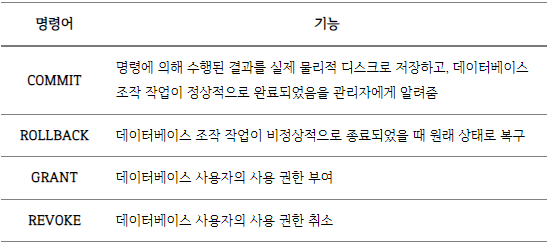
DBMS의 장단점
(생략)
| 장점 |
- 논리적, 물리적 독립성 보장 - 데이터의 중복을 최소화해 기억공간 절약 - 실시간 처리, 최신의 데이터 유지 - 다수 간의 데이터 공유 가능 - 데이터의 일관성, 무결성 유지 - 보안 기능 지원 |
| 단점 |
- 파일시스템에 비해 비용이 큼 - 한 부분에 장애가 생기면 전체 시스템에 영향을 주는 취약성이 있음 - 파일시스템에 비해 자료처리가 복잡함 |
DBMS의 종류
(1) Relational DBMS (관계형 데이터베이스 관리시스템, RDBMS)
- 지난 20년 간 SW시장에서 가장 많이 사용되었다 (Oracle, Microsoft, IBM, MySQL, PostgreSQL 등).
- 핵심적인 두 가지 특징이 있다.
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다. 따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다.
- 관계형 데이터 모델(ER 모델)을 도입한 DBMS로, 여러 개로 분산된 테이블 형태로 데이터들의 관계를 정의한다.
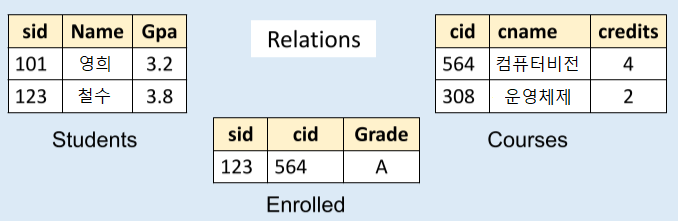
- 하나의 테이블에서 데이터를 중복 없이 한번만 저장하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 줄어드는 장점이 있다. 또한 관계를 맺고 있는 데이터가 자주 변경되는 경우, 데이터가 중복으로 저장되어 여러 컬렉션을 모두 수정해야 하는 NoSQL보다 효율적이다.
- 관계를 맺고 있어서 조인문이 많은 복잡한 쿼리가 만들어질 수 있다.
- SQL이라는 언어를 사용해 데이터를 다룬다.
(2) NoSQL (”Not Only SQL”)
- 관계형 DB의 반대이다. 스키마가 없거나 느슨한 스키마를 제공하고, 관계도 없다. 심지어 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
- 빅데이터의 등장으로 기존 RDBMS의 데이터 처리 비용이 증가하면서(RDBMS 특성상 분산 저장이 불가능해서 고성능의 하드웨어가 필요해졌기 때문이다) 나온 모델이다. 즉, 일관성을 약간 포기하고 대량의 분산된 데이터를 저장하고 조회하는 데 특화된 것을 목적으로 등장했다.
- 레코드를 문서(documents)라고 부른다. RDBMS처럼 여러 테이블에 나누지 않고, 관련된 모든 데이터를 동일한 ‘컬렉션’에 넣는다. 따라서 여러 테이블을 조인할 필요 없이 이미 필요한 모든 것을 갖추고 있다 (조인 개념이 없다).
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정시 모든 컬렉션에서 수행해야 한다.
- Hadoop MapReduce, Spark, Cassandra, Mongo 등