병행 제어의 종류
병행 제어(Concurrency Control)는 크게 비관적과 낙관적, 두가지 종류로 나뉜다.
-
비관적 병행 제어(Pessimistic Concurrency Control, 이하 PCC)
트랜잭션간 conflict가 많이 발생하는 “비관적”인 상황을 가정한다. 따라서 문제되는 작업을 사전에 막기 위해 conflict가 일어날 것 같은 곳에 lock을 거는 방법을 사용한다.
-
낙관적 병행 제어(Optimistic Concurrency Control, 이하 OCC)
Conflict가 별로 발생하지 않는 “낙관적” 상황을 가정한다. 따라서 일단 트랜잭션을 수행한 후, commit하기 전에 conflict가 발생했는지 확인하고, 발생했다면 트랜잭션을 abort하거나 repair하는 방법을 사용한다.
비관적 병행 제어 (PCC)
2 Phase Locking
2PL은 대표적인 PCC 기법이다. Conflict serializable 스케쥴을 만들기 위한 가장 흔한 방법이다. 요약하자면, conflict가 일어날 것 같은 곳에 미리 lock을 건다.
Lock을 거는 기본 원칙은 다음과 같다:
-
트랜잭션은 특정 레코드를 읽기 전에 레코드에 S(shared) 락을 걸고, 쓰기 전에 X(exclusive) 락을 걸어야 한다.
-
두 트랜잭션이 모두 S락을 걸었다면, 함께 데이터 접근을 허용할 수 있다. 둘 중 하나라도 X락을 건 경우, 먼저 락을 건 트랜잭션을 이후에 락을 걸러 온 트랜잭션이 기다려야 한다.
-
이를 표시한 표를 “Lock Compatibility Matrix”라 한다:
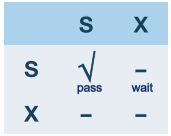
-
-
한 트랜잭션이 진행되는 동안 필요한 모든 락을 건 시점을 “lock point”라고 한다. 트랜잭션은 이 시점 이후부터 걸었던 락을 풀기 시작할 수 있으며, 락을 하나라도 푼 이후에는 다시 새로운 락을 걸 수 없다.
따라서 2PL에서 한 트랜잭션이 건 lock의 개수를 보면 다음과 같은 모습이다.
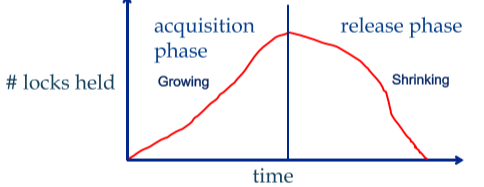
위에서 말했듯 2PL은 conflict serializability를 보장한다. Conflict serializability의 속성을 생각해보면 그 이유를 알 수 있는데, conflict serializability는 conflicting한 작업들의 순서를 트랜잭션의 순서에 그대로 반영하는 성질을 가진다. 2PL도 동일하다. Lock point 시점에서, 현재 트랜잭션과 conflict가 나는 다른 트랜잭션은 이미 이전에 락을 풀기 시작했거나, 해당 트랜잭션을 기다리며 멈춰있을 것이다. 따라서 conflicting한 두 트랜잭션은 lock point의 순서와 동일하게 스케쥴상 정렬된다.
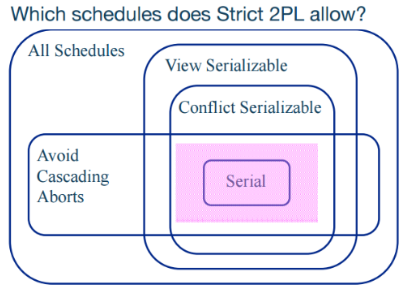
단, 2PL은 Cascading Abort를 막지 못한다. Cascading Abort(혹은 Cascading Rollback)란, 한 트랜잭션에 문제가 생겨 abort해야할 경우에 관련있는 다른 트랜잭션도 모두 abort돼야하는 상황이다. 예를 들어 다음과 같은 상황이다:

Strict 2PL은 이 문제를 막기 위해 고안된 방식이다.
Strict 2 Phase Locking
2PL과 비슷하지만, 잡았던 모든 락을 commit 혹은 abort+rollback이 완료된 시점에 “한꺼번에” 풀어서 Cascading abort를 방지한다.
Strict 2PL에서 한 트랜잭션이 건 lock의 개수를 보면 다음과 같다:
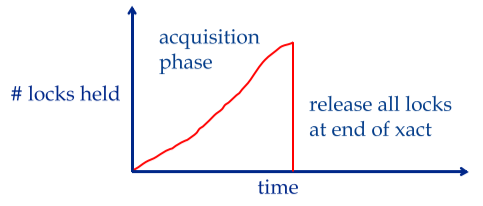
결론적으로, Strict 2PL은 Conflict Serializable 스케쥴 중에서도 Cascading Abort를 방지하는 스케쥴만을 허용한다:
Deadlock
데드락은 위 PCC 방법처럼 Lock을 사용할 때 반드시 해결해야하는 문제상황이다. 두개 이상의 트랜잭션이 서로 상대방이 건 락을 풀기를 끝없이 기다리고 있는 상황이다. 자세한 건 OS의 Deadlock 참고.
(처리 방법 생략)
데드락은 여러 처리방법이 있다(이 또한 자세한 건 OS의 Deadlock 참고):
-
Prevention
현재 데드락이 생긴 상황은 아니지만, 데드락의 가능성을 사전에 차단하는 방법이다. 먼저 각 트랜잭션에 트랜잭션이 시작한 타임스탬프에 기반한 순위를 부여한다. 얻으려는 락을 다른 트랜잭션이 선점해 기다려야하는 경우, 부여받은 순위에 따라 기다리거나, abort 시킨다.
예를 들어, 트랜잭션 T1과 T2가 있고 T1이 T2가 원하는 락을 선점한 상황에서, 두 가지 방법이 있다.
-
Wait-Die
한 락에 대해 기다리는 트랜잭션의 순위가 감소해야한다. T1이 순위가 높다면 abort하고, 낮다면 T2를 기다린다.
-
Wound-Wait
한 락에 대해 기다리는 트랜잭션의 순위가 증가해야한다. T1이 순위가 높다면 기다리고, 낮다면 abort한다.
-
-
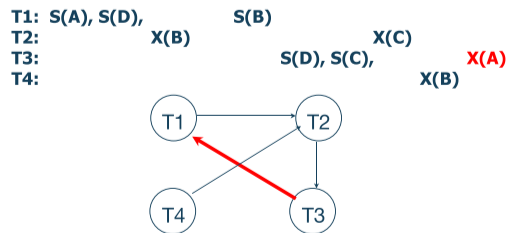
Detection
락을 일단 잡고, 백그라운드에서 데드락이 생겼는지 계속 확인하는 방법이다. Waits-for 그래프를 주기적으로 그리며 만약 사이클이 생긴다면 그 중 한 트랜잭션을 없앤다(”shoot”).
Multiple Granularity Locking Protocol
(생략)
Lock 단위에 granularity를 다르게 하는 것이다.
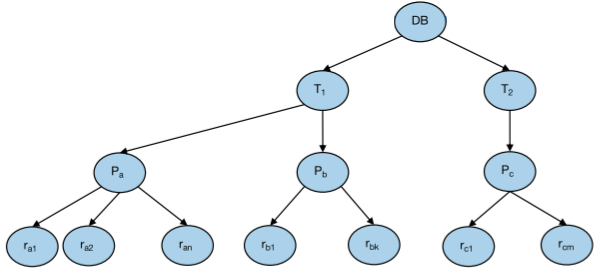
데이터의 granularity(분할 단위)는 트리 구조로 표현할 수 있다. 트리에서 위쪽 계층일 수록 Coarse 하고, 아래쪽 계층일 수록 Fine 하다고 표현한다.
Lock을 꼭 레코드가 아닌, 각 계층 (튜플, 페이지, 테이블, 데이터베이스 등) 단위로도 걸 수 있다. 또한, 모든 트랜잭션에 같은 단위의 locking을 적용할 필요는 없다.
트랜잭션이 트리의 한 노드를 “명시적으로” lock한다면, 이는 “암묵적으로” 해당 노드의 모든 자손 노드를 동일한 모드(X or S)로 lock한다. 따라서, Fine한 계층에 lock을 건다면 동시성은 높지만 locking 오버헤드가 높을 것이고, Coarse한 계층에 lock을 건다면 동시성은 낮지만 locking 오버헤드는 작을 것이다.
Intention Lock Mode
“Intent lock”은 락의 granularity가 다양해지며 생길 수 있는 문제상황을 방지하기 위해 사용하는 새로운 Lock 모드이다. 예를 들어, 한 트랜잭션이 테이블 내부의 튜플에 작업하는 도중에 다른 트랜잭션이 테이블 자체에 대한 수정을 하려할 수 있다. 이를 막으려면, 아래쪽 계층에서 작업이 이뤄지고 있음을 위쪽 계층이 알 수 있도록 해야 한다.
Intention Lock 프로토콜에선 어떤 데이터에 락을 걸기 전에 granularity 트리상 모든 조상 노드에 적합한 intent lock을 걸어야 한다. 다음과 같은 락 모드가 존재한다(실제론 훨씬 더 복잡하다):
- IS : 아래 계층에서 S 락을 걸 예정일 때
- IX : 아래 계층에서 X 락을 걸 예정일 때
- SIX : S + IX
이는 (1) 높은 계층의 자원을 수정해서 다른 트랜잭션이 낮은 계층에 건 락들을 무효화할 가능성이 있는 트랜잭션을 막을 수 있고 (2) 모든 자손 노드를 확인하지 않고도 아래 계층에서 작업이 일어나고 있는지 알 수 있어서 lock conflict를 감지하는 SQL 서버 데이터베이스 엔진의 효율을 높일 수 있다는 장점이 있다.
락을 풀 때는 아래에서 위로(bottom-up) 풀어야 한다.
Phantom 문제
팬텀(phantom) 문제는 한 트랜잭션 안에서 여러번 수행한 동일한 쿼리가 서로 다른 결과를 내는 Inconsistent Read 문제를 뜻한다. Serializability를 지원하는 모든 데이터베이스는 팬텀 문제를 막아야한다.
예를 들어, 트랜잭션이 한 테이블에서 ID가 10~20 사이인 모든 튜플을 골라내는 쿼리를 두 번 진행한다. 첫번째 쿼리를 완료한 이후, 다른 트랜잭션이 테이블에 ID가 12인 데이터를 삽입한다. 이후 두번째 쿼리에선 ID가 12인 튜플(즉 “팬텀”)이 포함된, 다른 결과가 출력된다.
Phantom 해결 방법
-
Index Locking
(Index를 사용한다는 가정 하에) 해당 데이터를 담고 있는 index “페이지”를 lock한다 (쿼리를 진행하는 필드에 대한 적절한 인덱스가 지어져있다면 해당 index 페이지만 lock하면 되고, 적절한 인덱스가 없다면 모든 페이지와 파일/테이블을 lock해야한다). 동시성이 매우 떨어져 사용하지 않는 것이 좋다.
-
Predicate Locking
특정 predicate을 만족하는 모든 레코드에 대해 lock한다. (Index locking이 predicate locking의 일종이다) 보통 락킹 오버헤드가 크다.
-
Gap Locking
현재 데이터베이스에서 사용하는 방식이다. Gap Lock은 레코드 간의 “gap”에 걸리는 Lock이다. 여기서 gap이란 index 중 DB에 실제 record가 없는 부분이다. Gap Lock은 해당 gap에 접근하려는 다른 쿼리의 접근을 막는다. Locking된 gap에 삽입/삭제/업데이트를 시도하면, gap lock을 건 트랜잭션이 commit/abort 될 때까지 삽입/삭제/업데이트 되지 않는다.
PCC의 문제점
PCC는 다음과 같은 문제를 가진다:
- Locking 오버헤드가 발생한다.
- 데드락을 탐색하고 해결해야한다.
- 자주 사용되는 오브젝트에 대해 lock contention(여러 트랜잭션이 자원을 두고 경쟁함)이 발생한다.
이는 전부 lock을 사용하기 때문에 발생하는 문제들이다. 따라서 conflict가 적은 상황에선 lock을 사용하지 않는 OCC를 사용할 수 있다.
낙관적 병행 제어 (OCC)
OCC에선 conflict가 적다는 가정 하에, 아무런 제약 없이 레코드에 접근하도록 허용하고 트랜잭션이 write하기 직전에 (트랜잭션 시작 이후로 다른 트랜잭션에 의해 레코드 값이 변경됐는지) conflict를 확인한다.
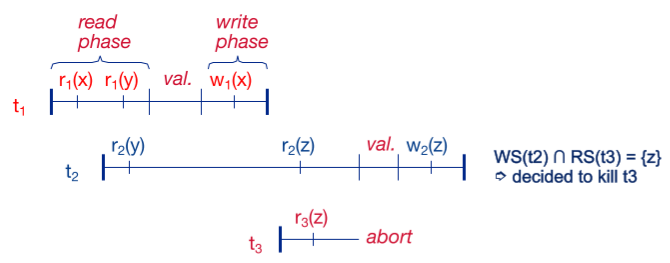
OCC에서 트랜잭션은 3 단계로 나뉜다: read - validation(certifier) - write. Validation 단계에서 다른 트랜잭션의 작업과 현재 트랜잭션의 작업을 비교해 conflict가 발생하지 않았다는 조건을 만족해야 write하고 commit할 수 있다. 조건을 만족하지 못한다면 둘 중 한 트랜잭션을 abort한다. 이 validation 단계에서 ‘어떤’ 트랜잭션과 비교할 지에 따라 OCC의 종류가 backward, forward로 나뉜다.
Backward-oriented OCC
“이전” 트랜잭션과 비교한다.

Forward-oriented OCC
“이후” 트랜잭션과 비교한다.
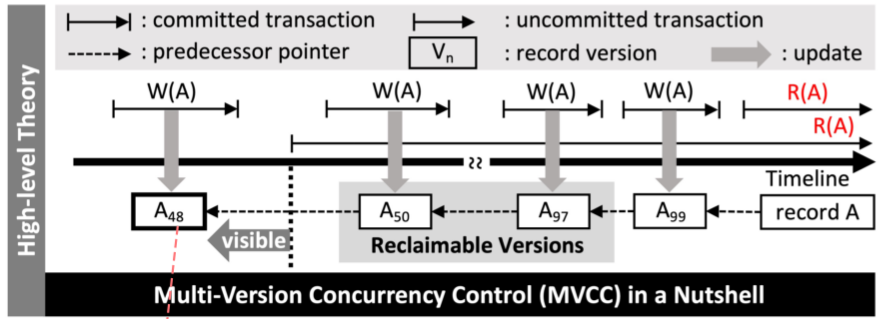
Snapshot Isolation (SI) 혹은 Multiversion Concurrency Control(MVCC)
한 트랜잭션은 진행되는 동안 언제나 자신이 시작한 시점의 데이터베이스의 snapshot(사진을 찍은듯 정지된 상태)을 읽는다(예외: 현재 트랜잭션이 수정한 데이터는 수정한 값으로 읽는다). 트랜잭션이 commit할 때까지 만들어진 변경사항은 다른 트랜잭션이 읽을 수 없다. 값을 update하면 이전 데이터를 덮어씌우는 게 아니라 새로운 버전의 데이터를 UNDO 영역에 생성한다. 이렇게 해서 하나의 데이터에 여러 버전이 존재하게 되고, 트랜잭션은 마지막 버전의 데이터를 읽게 된다.
트랜잭션을 commit 할지 rollback 할지 결정하는 기준은 구현마다 다르지만, 예를 들어 동시에 접근한 트랜잭션 중 첫번째로 커밋한 트랜잭션만 살아남고 나머지는 모두 rollback하는 방법이 있다. “First-committer-wins” rule이라 한다.
Lock이 필요하지 않기 때문에 일반적인 RDBMS보다 훨씬 빠르다는 장점이 있다. 특히 read 작업은 절대 block되지 않는다. Dirty read, lost update, inconsistent read, phantom 등 문제가 사라진다.
하지만 사용하지 않는 데이터가 계속 쌓이게 되므로 데이터 정리 시스템이 필요하다는 단점도 있다. 특히 long-lived 트랜잭션이 큰 골칫거리다. 또한 serializability를 완벽하게 보장하지 않는다!