Crash Recovery
데이터베이스의 고장(failure)은 여러 이유로 발생한다. 트랜잭션 실패(비정상적 인풋 등의 내부적인 에러 조건, 데드락 등), 시스템 충돌(HW, SW, OS의 문제로 휘발성 저장장치의 내용을 잃지만, 비휘발성 저장장치 내용은 남아있는 경우), 디스크 고장 등이다.
Crash Recovery는 데이터베이스가 시스템 충돌로 인해 비정상적으로 종료됐을 때, 재시작하는 과정에서 이전 상태로 회복하는 단계를 말한다. 이는 트랜잭션의 ACID 성질 중 Atomicity 와 Durability를 보장하기 위함이다. 회복을 하기위해선 Undo 또는 Redo 과정을 거쳐야 한다.
- UNDO : 사용자가 했던 작업을 반대로 진행하는 것 (트랜잭션 이전 상태로 복구)
- REDO : 사용자가 했던 작업을 그대로 다시하는 것 (트랜잭션 이후 상태로 복구)
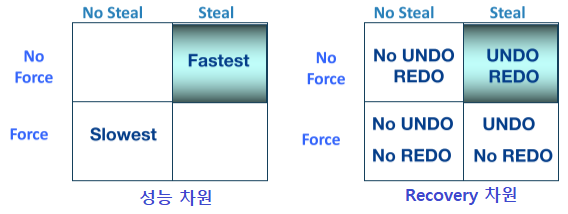
Recovery 프로토콜을 정하는 데 버퍼 매니저의 policy가 주요 역할을 한다. 4가지 버퍼 policy가 있다:
-
FORCE : 트랜잭션이 업데이트한 내용이 버퍼에 남아있다면, 해당 트랜잭션이 커밋하기 전에 디스크에 반드시 반영해야한다.
⇒ 커밋한 트랜잭션의 데이터는 반드시 디스크에 반영돼있기 때문에 failure가 일어나도 REDO 작업이 필요없다. 따라서 Durability를 보장하지만, 성능 ↓
-
NO FORCE : 트랜잭션이 커밋할 때, 버퍼에 남아있는 트랜잭션의 업데이트 내용을 꼭 디스크에 반영하지 않아도 된다 (이후 페이지 eviction 등이 발생할 때 차차 반영한다).
⇒ 문제는 업데이트된 내용이 디스크에 적히기 전에 failure가 발생하는 상황이다. 트랜잭션이 커밋했으니 디스크에 반영돼있어야 하는데, 업데이트된 내용이 아직 버퍼(메모리)에만 있었으므로 failure시 사라진다.
⇒ 이렇게 커밋한 트랜잭션의 사라진 업데이트를 다시 해주기 위해 REDO 작업이 필요하다.
-
NO STEAL : 커밋되지 않은 트랜잭션이 업데이트한 내용을 디스크에 반영하지 않는다. 즉, 업데이트한 내용이 담긴 페이지를 버퍼에서 evict 시키지 않는다.
⇒ 커밋되지 않은 트랜잭션의 데이터는 디스크에 반영되지 않기 때문에 failure가 일어났을 때 UNDO 작업이 필요없다. 따라서 Atomicity를 보장하지만, 성능 ↓
-
STEAL : 커밋되지 않은 트랜잭션이 업데이트한 내용이 담긴 페이지라도, 버퍼에서 페이지를 evict 할 수 있다. 즉, 디스크에 반영될 수 있다.
⇒ 문제는 이후 해당 트랜잭션이 abort되거나, 트랜잭션이 커밋하기 전에 failure가 발생하는 상황이다. 트랜잭션이 커밋하지 못했으니 디스크에 반영되면 안 되는데, 업데이트된 내용이 일부 디스크에 반영돼있다.
⇒ 이렇게 커밋하지 못한 트랜잭션이 반영한 업데이트를 제거하기 위해 UNDO 작업이 필요하다.
Logging
그럼 어떤 작업을 UNDO 하고 REDO 해야할 지는 어떻게 알 수 있을까? 이를 위해 DBMS는 로그(log)를 작성한다. 로그란 데이터 수정 사항을 기록한 레코드가 순차적으로 저장된 파일이다.
각각의 로그 레코드는 다음과 같은 정보를 포함한다:
 |
- LSN : 각 로그 레코드의 고유한 식별자이며, 값은 계속 증가한다. - XID : 로그를 만든 트랜잭션의 ID - type : 로그 타입(begin, commit, write 등) - pageID : 업데이트한 페이지 넘버 - length : 업데이트한 내용의 길이 - offset : 페이지 내부 offset - before : 업데이트 이전 내용 - after : 새로운 내용 |
ARIES (Algorithms for Recovery and Isolation Exploiting Semantics)
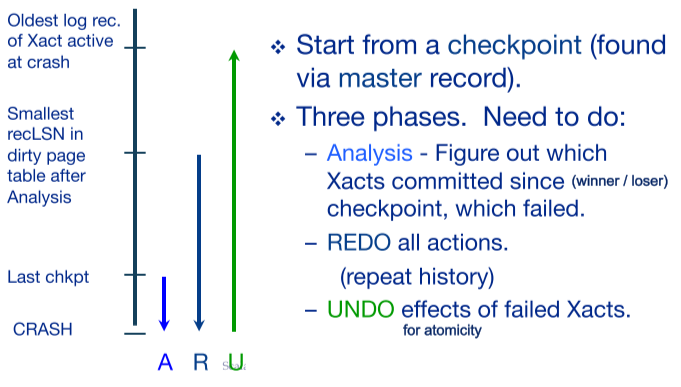
Failure가 일어난 후, Recovery 단계에서 디스크에 적힌 로그를 확인하며 REDO/UNDO를 실행한다. Recovery는 3 단계로 이뤄진다.
-
Analysis
begin 로그 레코드를 남긴 트랜잭션이 commit 로그 레코드까지 남겼다면 성공적으로 커밋한 것이고, 그렇지 못했다면 커밋하기 전에 failure가 발생한 실패한 트랜잭션임을 확인할 수 있다.
-
Redo
커밋한 트랜잭션에 대해: 디스크 페이지에 기록된 LSN이 가장 최근 로그에 기록된 LSN보다 작다면, 반영하지 못한 업데이트 사항이 있다는 뜻이다. 따라서 로그를 참고해 REDO 작업을 해준다.
- 참고로, 성공적으로 commit 혹은 rollback을 마친 Winner 트랜잭션에 대해서만 REDO 작업을 하는 “Redo-Winners” 방식과, Winner와 그렇지 못한 Loser 트랜잭션의 모든 작업을 REDO한 후, Loser의 내용을 UNDO하는 “Redo-History” 방식이 있다.
-
Undo
커밋하지 못한 트랜잭션에 대해: 디스크 페이지에 기록된 LSN이 가장 옛날 로그에 기록된 LSN보다 크다면, 반영해버린 업데이트 사항이 있다는 뜻이다. 따라서 로그를 참고해 UNDO 작업을 해준다.
Write-Ahead Logging (WAL)
아주 많은 Steal/No Force 시스템이 로그의 정확성을 보장하기 위해 WAL policy를 사용한다. WAL은:
- UNDO를 위해 업데이트 내용이 담긴 페이지를 디스크에 반영하기 전에, 해당 업데이트에 대한 로그 레코드를 디스크에 적어야한다.
-
REDO를 위해 트랜잭션이 커밋하기 전에, 해당 트랜잭션이 생성한 모든 로그 레코드를 디스크에 적어야한다.

Checkpointing
중간 세이브와 비슷한 개념이다. 현재 메모리(버퍼) 내 업데이트 사항이 있는 모든 더티 페이지와 로그 레코드를 디스크에 적어준다. Checkpointing을 자주 했을 때의 장점은 failure에 의한 복구가 필요할 때 마지막 checkpoint 이후의 변경사항에 대해서만 복구를 시도하면 되므로 복구 시간이 단축된다는 점이다. 단점은 checkpoint하는 동안 성능이 확 떨어진다.