(생략)
목차
- 데이터베이스의 성능
- SQL injection
- CAP 이론
- 저장 방식에 따른 NoSQL 분류
- 확장 개념
- 정규화
- 인덱스
- 트랜잭션
- Statement vs PreparedStatement
데이터베이스의 성능?
데이터베이스의 성능 이슈는 디스크 I/O 를 어떻게 줄이느냐에서 시작된다. 디스크 I/O 란 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미한다. 이 때 데이터를 읽는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 따라 결정된다고 볼 수 있다.
그렇기 때문에 순차 I/O 가 랜덤 I/O 보다 빠를 수 밖에 없다. 하지만 현실에서는 대부분의 I/O 작업이 랜덤 I/O 이다. 랜덤 I/O 를 순차 I/O 로 바꿔서 실행할 수는 없을까? 이러한 생각에서부터 시작되는 데이터베이스 쿼리 튜닝은 랜덤 I/O 자체를 줄여주는 것이 목적이라고 할 수 있다.
SQL injection
- 해커에 의해 조작된 SQL 쿼리문이 데이터베이스에 그대로 전달되어 비정상적 명령을 실행시키는 공격 기법을 말한다.
공격 방법
- 인증 우회 : 비밀번호를 입력하며 쿼리를 넣는 등
- 데이터 노출 : 시스템에서 발생하는 에러 메시지를 이용해 공격
방어 방법
- input 값을 받을 때, 특수 문자 여부 검사하기
- (View를 활용해) SQL 서버 오류 발생 시, 해당하는 에러 메시지 감추기
- prepare statement 사용하기 (특수문자를 자동으로 escaping 해준다)
CAP 이론
CAP 정리에 의하면 시스템은 일관성, 가용성, 분단 허용성 중에서, 두 가지 속성만 가질 수 있다.
-
일관성(Consistency)
데이터를 저장하는 장비가 여러대라도 모든 장비에서 동일한 데이터가 저장되어 있어야 한다는 것이다. ACID 원리에서 의미하는 것과 같다. 따라서 트랜잭션 또는 비슷한 매커니즘이 필요하다.
-
가용성(Availability)
죽지 않은 상태의 모든 서버는 클라이언트에게 항상 정상 처리 응답을 보내주어야 한다는 것을 의미한다. 클라이언트가 읽기, 쓰기 요청을 하면 제대로 읽고 쓰는 작업을 해야한다. 현재 시스템에 문제가 있어서 읽을 수 없다고 보내면 가용성이 보장되지 않는 것을 뜻한다.
-
네트워크 분할 허용성(Partition tolerance)
클러스터가 여러 대 동작하고 있을 때, 해당 클러스터 사이에 접속이 단절되어 서로 통신을 할 수 없는 상황에서도 시스템이 잘 동작해야 한다는 것이다.
관계형 데이터베이스는 CA 시스템이다(동시에 다량의 서버를 운용하는 클러스터링에 적합하지 않은 이유). 대부분의 NoSQL은 CP나 AP 시스템이다. 참고로, 대용량의 분산 시스템을 구축하는데에는 CP보다도 AP가 알맞다.
저장 방식에 따른 NoSQL 분류
Key-Value Model, Document Model, Column Model, Graph Model로 분류할 수 있다.
확장 개념
두 데이터베이스를 비교할 때 중요한 Scaling 개념도 존재한다. 데이터베이스 서버의 확장성은 수직적 확장과 수평적 확장으로 나누어진다.
- 수직적 확장 : 단순히 데이터베이스 서버의 성능을 향상시키는 것(ex. CPU 업그레이드)
- 수평적 확장 : 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산됨을 의미한다.(하나의 데이터베이스에서 작동하지만, 여러 호스트에서 작동)
데이터 저장 방식으로 인해 SQL DB는 일반적으로 수직적 확장만 지원한다. 수평적 확장은 NoSQL DB에서만 가능하다.
정규화
정규화를 해야 하는 이유는 잘못된 테이블 설계로 인해 Anomaly(이상 현상)가 나타나기 때문이다.
한 릴레이션에 여러 엔티티의 애트리뷰트들을 혼합하게 되면 정보가 중복 저장되며 저장 공간을 낭비하고, 다음 이상이 생길 수 있다.
- 삽입 이상(Insertion Anomaly) : 불필요한 데이터를 추가해야 삽입할 수 있는 상황
- 갱신 이상(Update Anomaly) : 일부의 테이블에서만 변경되어 데이터가 불일치하는 모순의 문제
- 삭제 이상(Deletion Anomaly) : 튜플 삭제로 인해 꼭 필요한 데이터까지 함께 삭제되는 문제
따라서 정규화는 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업이다. 구체적으로는 나쁜 릴레이션의 속성들을 좋은 작은 릴레이션으로 나눈다.
- ‘나쁜 릴레이션’은 어떻게 파악하는가? 엔티티를 구성하고 있는 속성 간에 함수적 종속성(Functional Dependency)을 판단한다. 판단된 함수적 종속성은 좋은 릴레이션 설계의 정형적 기준으로 사용된다. 즉, 각각의 정규형마다 어떠한 함수적 종속성을 만족하는지에 따라 정규형이 정의되고, 그 정규형을 만족하지 못하는 정규형을 나쁜 릴레이션으로 파악한다.
- 함수적 종속성이란? 어떤 릴레이션의 X와 Y를 각각 속성의 부분집합이라고 가정해봅니다. 여기서 X의 값을 알면 Y의 값을 바로 식별할 수 있고, X의 값에 Y의 값이 달라질 때, Y는 X에 함수적 종속이라고 합니다
정규화 과정을 거치게 되면 정규형을 만족하게 된다. 정규형이란 특정 조건을 만족하는 릴레이션의 스키마의 형태를 말한다.
- 각각의 정규형은 어떠한 조건을 만족해야 하는가?
- 분해의 대상인 분해 집합 D 는 무손실 조인을 보장해야 한다.
- 분해 집합 D 는 함수적 종속성을 보존해야 한다.
제 1 정규형
애트리뷰트의 도메인이 오직 원자값만을 포함하고, 튜플의 모든 애트리뷰트가 도메인에 속하는 하나의 값을 가져야 한다. 즉, 복합 애트리뷰트, 다중값 애트리뷰트, 중첩 릴레이션 등 비 원자적인 애트리뷰트들을 허용하지 않는 릴레이션 형태를 말한다.
제 2 정규형
모든 비주요 애트리뷰트들이 주요 애트리뷰트에 대해서 완전 함수적 종속이면 제 2 정규형을 만족한다고 볼 수 있다. 완전 함수적 종속이란 X -> Y 라고 가정했을 때, X 의 어떠한 애트리뷰트라도 제거하면 더 이상 함수적 종속성이 성립하지 않는 경우를 말한다. 즉, 키가 아닌 열들이 각각 후보키에 대해 결정되는 릴레이션 형태를 말한다.
제 3 정규형
어떠한 비주요 애트리뷰트도 기본키에 대해서 이행적으로 종속되지 않으면 제 3 정규형을 만족한다고 볼 수 있다. 이행 함수적 종속이란 X - >Y, Y -> Z의 경우에 의해서 추론될 수 있는 X -> Z의 종속관계를 말한다. 즉, 비주요 애트리뷰트가 비주요 애트리뷰트에 의해 종속되는 경우가 없는 릴레이션 형태를 말한다.
BCNF(Boyce-Codd) 정규형
여러 후보 키가 존재하는 릴레이션에 해당하는 정규화 내용이다. 복잡한 식별자 관계에 의해 발생하는 문제를 해결하기 위해 제 3 정규형을 보완하는데 의미가 있다. 비주요 애트리뷰트가 후보키의 일부를 결정하는 분해하는 과정을 말한다.
각 정규형은 그의 선행 정규형보다 더 엄격한 조건을 갖는다.
- 모든 제 2 정규형 릴레이션은 제 1 정규형을 갖는다.
- 모든 제 3 정규형 릴레이션은 제 2 정규형을 갖는다.
- 모든 BCNF 정규형 릴레이션은 제 3 정규형을 갖는다.
수많은 정규형이 있지만 관계 데이터베이스 설계의 목표는 각 릴레이션이 3NF(or BCNF)를 갖게 하는 것이다.
정규화의 장점
- 이상 현상 제거
- 정규화된 데이터베이스 구조는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다. 이는 연동된 응용 프로그램에 최소한의 영향만을 미쳐 프로그램의 생명을 연장시킨다.
- 현실 세계에서의 개념들과 관계들을 반영하기 때문에 사용자에게 더욱 의미있는 데이터모델을 제공한다.
정규화의 단점
- 릴레이션의 분해로 인해 JOIN 연산이 많아져 질의 응답 시간이 느려질 수 있다. 조금 덧붙이자면, 정규화를 수행한다는 것은 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반 속성을 의존자로 하여 입력/수정/삭제 이상을 제거하는 것이다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다. 따라서 정규화된 테이블은 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있는 특성이 있다.
반정규화 **(De-normalization, 비정규화)**
조인이 많이 발생하여 성능 저하가 나타나는 경우에 반정규화를 적용하는 전략이 필요하다.
정규화된 엔티티, 속성, 관계를 중복 통합, 분리 등을 수행하는 데이터 모델링 기법이다. 디스크 I/O 량이 많아서 조회 시 성능이 저하되거나, 테이블끼리의 경로가 너무 멀어 조인으로 인한 성능 저하가 예상되거나, 칼럼을 계산하여 조회할 때 성능이 저하될 것이 예상되는 경우 반정규화를 수행하게 된다. 일반적으로 조회에 대한 처리 성능이 중요하다고 판단될 때 부분적으로 반정규화를 고려하게 된다.
- 반정규화의 대상
- 자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
- 주의할 점
반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있다. 또한 입력, 수정, 삭제의 질의문에 대한 응답 시간이 늦어질 수 있다.
인덱스
- RDBMS에서 검색 속도를 높이기 위해 사용하는 하나의 기술, 색인이다.
- Table의 컬럼을 색인화(따로 파일로 저장)하여 검색시 해당 Table을 full scan하는게 아니라 색인화 되어있는 INDEX 파일을 검색하여 검색 속도를 빠르게 한다.
- Tree 구조로 색인화하며, RDBMS에서 사용하는 INDEX는 Balance Search Tree를 사용한다. Hash 인덱스 알고리즘이라는 것도 있지만 부등호 연산이 어려워 주로 메모리 기반의 데이터베이스에서만 많이 사용한다.
INDEX의 원리
INDEX를 해당 컬럼에 주게 되면 초기 Table 생성시, FRM, MYD, MYI 3개의 파일이 만들어진다.
- FRM : 테이블 구조가 저장되어 있는 파일
- MYD : 실제 데이터가 있는 파일
- MYI : INDEX 정보가 들어있는 파일
INDEX를 사용하지 않는 경우, MYI가 비어 있다. INDEX를 해당 컬럼에 만들게 되면 해당 컬럼을 따로 인덱싱하여 MYI 파일에 입력한다.
이후에 사용자가 SELECT 쿼리로 INDEX를 사용하는 쿼리를 사용시 해당 Table을 검색하는 것이 아니라 MYI 파일의 내용을 검색한다. 만약, INDEX를 사용하지 않은 SELECT 쿼리라면 해당 Table Full scan하여 모두 검색한다.
PRIMARY INDEX
프라이머리 키 값이 비슷한 레코드끼리 묶어서 저장하는 것을 클러스터드 인덱스라고 표현한다. 클러스터드 인덱스에서는 프라이머리 키 값에 의해 레코드의 저장 위치가 결정되며 프라이머리 키 값이 변경되면 그 레코드의 물리적인 저장 위치 또한 변경되어야 한다.
클러스터드 인덱스는 테이블 당 한 개만 생성할 수 있다. 프라이머리 키에 대해서만 적용되기 때문이다. 이에 반해 non 클러스터드 인덱스(SECONDARY INDEX)는 테이블 당 여러 개를 생성할 수 있다.
COMPOSITE INDEX
두개 이상의 속성을 묶어 키로 사용하는 경우다. 인덱스로 설정하는 필드의 속성이 중요하다. title, author 순서로 인덱스를 설정한다면 title 을 검색하는 경우, index 를 생성한 효과를 볼 수 있지만, author 만으로 검색하는 경우, index 를 생성한 것이 소용이 없어진다.
장점
- 검색과 정렬 속도를 향상시킨다.
- 정렬된 상태를 유지해야 하기 때문에 DELETE, INSERT, UPDATE 쿼리는 INDEX 사용시 오히려 좀 느려진다.
- 테이블 행의 고유성을 강화시킬 수 있다.
- 테이블의 기본키는 자동으로 인덱스된다.
- 필드 중에는 데이터 형식 때문에 인덱스 될 수 없는 필드도 있다.
- 여러 필드로 이루어진(다중 필드)인덱스를 사용하면 첫 필드 값이 같은 레코드도 구분할 수 있다. 참고로 액세스에서 다중 필드 인덱스는 최대 10개의 필드를 포함할 수 있다.
단점
- 인덱스를 만들면 .mdb 파일 크기가 늘어난다.
- 사용자가 한 페이지를 동시에 수정할 수 있는 병행성이 줄어든다.
- 인덱스된 필드에서 데이터를 업데이트하거나 레코드를 추가 또는 삭제할 때 성능이 떨어진다.
- 인덱스가 데이터베이스 공간을 차지해 DB의 10% 내외의 공간이 추가로 필요하다.
- 인덱스를 생성하는데 시간이 많이 소요될 수 있다.
- 데이터 변경 작업이 자주 일어날 경우에 인덱스를 재작성해야 할 필요가 있기에 성능에 영향을 끼칠 수 있다.
인덱스를 추가하면 쿼리 속도가 1초 정도 빨라지지만, 데이터 행을 추가하는 속도는 2초 정도 느려지게 되어 여러 사용자가 사용하는 경우, 레코드 잠금 문제가 발생할 수 있다.
또, 다른 필드에 대한 인덱스를 만들게 되면 성능이 별로 향상되지 않을 수도 있다. 가장 고유한 값을 갖는 필드만 인덱스해야 한다.
[사용하면 좋은 경우]
- Where절에서 자주 사용되는 Column
- WHERE절에 사용되는 칼럼이라고 전부 인덱스로 생성하면 데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해져서 오히려 역효과만 불러올 수 있다.
- 외래키가 사용되는 Column
- Join에 자주 사용되는 Column
[Index 사용을 피해야 하는 경우]
- Data 중복도가 높은 Column
- DML이 자주 일어나는 Column
DML에 취약
- INSERT
- indext split : 인덱스의 Block들이 하나에서 두개로 나누어지는 현상.
- 인덱스는 데이터가 순서대로 정렬되어야 한다. 기존 블록에 여유 공간이 없는 상황에서 그 블록에 새로운 데이터가 입력되어야 할 경우, 오라클이 기존 블록의 내용 중 일부를 새 블록에다가 기록한 후, 기존 블록에 빈 공간을 만들어서 새로운 데이터를 추가하게 된다.
- 성능면에서 매우 불리하다.
- Index split은 새로운 블록을 할당받고 Key를 옮기는 복잡한 작업을 수행한다. 모든 수행 과정이 Redo에 기록되고 많은 양의 Redo를 유발한다.
- Index split이 이루어지는 동안 해당 블록에 대해 키 값이 변경되면 안되므로 DML이 블로킹된다.
- DELETE
- 테이블에서 데이터가 Delete될 경우, 지워지고 다른 데이터가 그 공간을 사용할 수 있다.
- index에서 데이터가 delete될 경우, 데이터가 지워지지 않고 사용 안됨 표시만 해둔다.
- 즉, row 수가 그대로이며, 테이블에 데이터가 1만건 있어도 인덱스에는 2만건이 있을 수 있다는 뜻이다.
- 인덱스를 사용해도 수행 속도를 기대하기 힘들다.
- UPDATE
- 인덱스에는 Update 개념이 없다.
- 테이블에 update가 발생할 경우, 인덱스에서는 delete가 먼저 발생한 후 새로운 작업의 insert 작업이 발생한다.
- delete와 insert 두 개의 작업이 인덱스에서 동시에 일어나 다른 DML보다 더 큰 부하를 주게 된다.
트랜잭션
트랜잭션의 상태
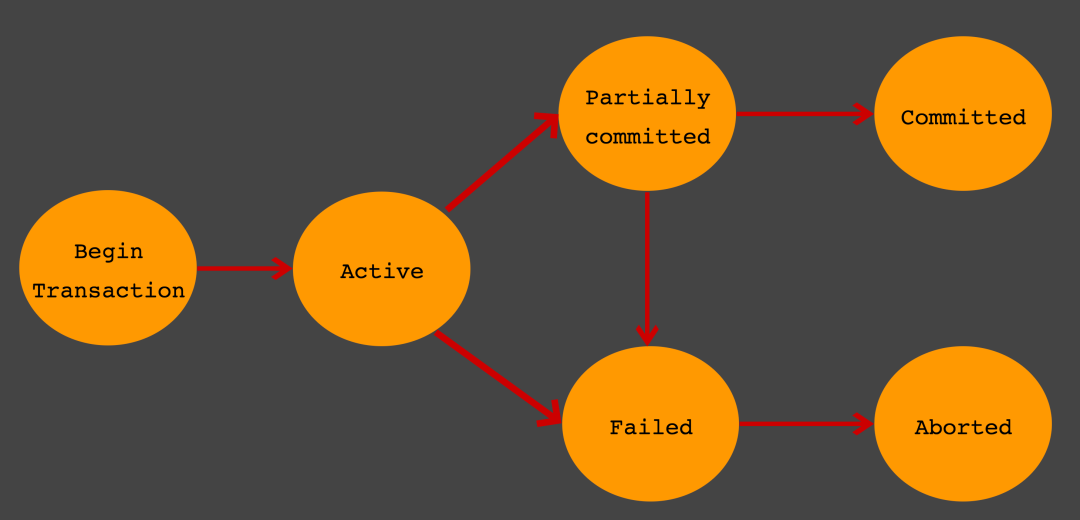
트랜잭션을 사용할 때 주의할 점
트랜잭션은 꼭 필요한 최소의 코드에만 적용하는 것이 좋다. 즉 트랜잭션의 범위를 최소화하라는 의미다. 일반적으로 데이터베이스 커넥션은 개수가 제한적이다. 그런데 각 단위 프로그램이 커넥션을 소유하는 시간이 길어진다면 사용 가능한 여유 커넥션의 개수는 줄어들게 된다. 그러다 어느 순간에는 각 단위 프로그램에서 커넥션을 가져가기 위해 기다려야 하는 상황이 발생할 수도 있는 것이다
교착 상태의 빈도를 낮추는 방법
복수의 트랜잭션을 사용하다보면 교착상태가 일어날수 있다. (개념 생략)
- 트랜잭션을 자주 커밋한다.
- 트랜잭션들이 동일한 테이블 순으로 접근하게 한다.
- 읽기 잠금 획득 (SELECT ~ FOR UPDATE)의 사용을 피한다.
- 한 테이블의 복수 행을 복수의 연결에서 순서 없이 갱신하면 교착상태가 발생하기 쉽다, 이 경우에는 테이블 단위의 잠금을 획득해 갱신을 직렬화 하면 동시성을 떨어지지만 교착상태를 회피할 수 있다
Statement vs PreparedStatement
가장 큰 차이점은 캐시(cache) 사용여부이다. 쿼리는 다음 과정을 거쳐 처리되는데:
- 쿼리 분석 (Parse the incoming SQL query)
- 컴파일 (Compile the SQL query)
- Plan/optimize the data acquisition path
- 실행 (Execute the optimized query / acquire and return data)
Statement를 사용하면 매번 쿼리를 수행할 때마다 1~4 단계를 거친다. PreparedStatement는 1~3 단계를 pre-execute 하고 캐시에 담아 재사용을 한다.
-
비교
우선 속도 면에서 Prepared Statement가 빠르다고 알려져 있다. 이유는 쿼리를 수행하기 전에 이미 쿼리가 컴파일 되어 있으며, 반복 수행의 경우 프리 컴파일된 쿼리를 통해 수행이 이루어지기 때문이다.
Statement에는 보통 변수를 설정하고 바인딩하는static sql이 사용되고Prepared Statement에서는 쿼리 자체에 조건이 들어가는dynamic sql이 사용된다.PreparedStatement가 파싱 타임을 줄여주는 것은 분명하지만dynamic sql을 사용하는데 따르는 퍼포먼스 저하를 고려하지 않을 수 없다.하지만 성능을 고려할 때 시간 부분에서 가장 큰 비중을 차지하는 것은 테이블에서 레코드(row)를 가져오는 과정이고 SQL 문을 파싱하는 시간은 이 시간의 10 분의 1 에 불과하다. 그렇기 때문에
SQL Injection등의 문제를 보완해주는PreparedStatement를 사용하는 것이 옳다.