CPU Scheduling
들어가기 전에
CPU scheduling 은 현대 다수의 프로그램이 실행되는 OS 에 필수적인 개념입니다. 실행되는 process 를 switching 하면서 OS 는 컴퓨터의 작업을 더 효율적이게 합니다.
이 단원에서 우리는 기본적인 CPU scheduling concept 을 알아보고 현대에 사용되는 scheduling 방식에 대해 알아볼 것입니다.
Basic Concepts
CPU - I/O Burst
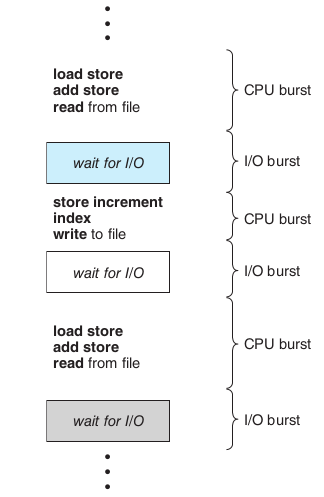
Process 는 통상적으로 CPU execution 과 I/O wait 을 반복하며 실행이 됩니다.
여기에서 process 가 CPU 에 의해 실행되는 구간, 시간을 CPU burst 라고 하고 process 가 I/O request 를 보내 기다리는 시간을 I/O burst 라고 합니다.
CPU Scheduler
CPU scheduler은 process가 CPU 를 놓아줄 때 다음엔 어떤 process가 CPU를 차지해야하는지 Ready Queue 에서 골라주는 주체입니다.
Ready Queue 에서 process 선택의 방식은 FIFO 가 아니라 다양한 metric 에 따라 달라집니다.
Dispatcher
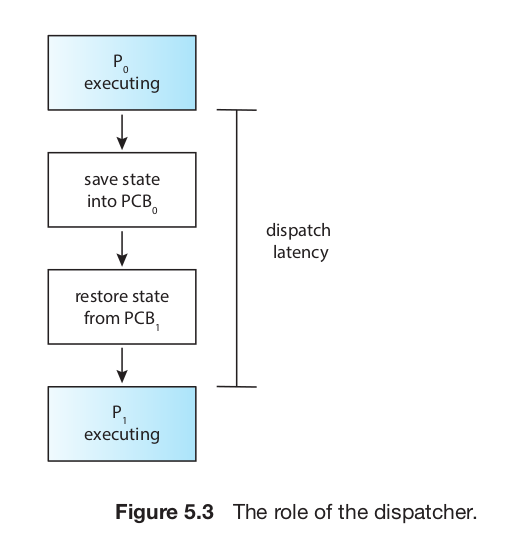
우리가 흔히 말하는 process scheduling은 넓은 의미의 scheduling 으로 CPU에 올릴 process 를 고르는 scheduling 작업, 고른 process를 CPU에 올리는 dispatch작업으로 나뉠 수 있습니다.
Dispatcher은 process에게 CPU의 control을 주는 역할을 합니다. 이를 위해서 dispatcher가 하는 일들은
- context switching
- user mode 로 switching
- user program 의 해당 주소값으로 찾아갈 수 있도록 하는 일
이정도가 되겠습니다.
Preemptive & Non-preemptive Scheduling
CPU scheduler 은 아래 4가지 경우에 발동할 것입니다.
- running → waiting
- running → ready
- waiting → ready
- process 종료시
1,4 의 상황에서는 무조건 scheduling 이 일어나야 하지만, 2와 3 상황에서는 선택의 여지가 있습니다.
이 상황들에서 non-preemptive scheduling(비선점형 스케줄링)(cooperative scheduling 라고도 함) 은 1,4 상황에서만 스케줄링이 발생하고, 2,3 상황에선느 스케줄링이 발생하지 않습니다. 이는 어떤 process가 CPU를 할당 받으면 그 process가 terminate 되거나 IO request 가 발생할 때 말고는 강제적으로 scheduling이 발생하지 않는다는 말입니다. 그래서 보통 non-preemptive한 scheduling 방식을 택한 OS는 scheduler 호출 빈도가 낮고 context-switch overhead 가 적습니다. 그리고 하나의 process 가 끝나기 전까지, 자발적으로 ready상태로 들어가지 않고는 계속 CPU를 차지하고 있게 됩니다.
반면에 preemptive scheduling(선점형 스케줄링) 에서는 1~4 상황 모두에서 scheduling이 일어나 CPU를 차지하는 process 가 교체됩니다.
어떤 process가 실행되다가 주어진 시간을 모두 사용해 time-out 되거나, IO request, termination등등의 상황에서 scheduling이 발생하여 CPU를 다른 process에게 넘기게 됩니다. 현대 운영체제인 Windows, macOS, Linux, UNIX 은 모두 preemptive한 방식을 채택하여 사용하고 있습니다.
하지만 preemptive 한 방식은 race condition 을 발생하여 이를 해결하기 위한 별도의 방식이 필요합니다.
Scheduling Criteria
그럼 scheduler가 scheduling 하는 과정에서 어떤 기준으로 scheduling 방식을 채택하고 성능을 측정하는지 알아봅시다.
CPU utilization : CPU 이용률
“CPU 가 놀지않고 얼마나 많이 사용되는가”
Throughput : 처리량
단위시간당 처리하는 일의 양
Scheduling에서는 instruction per second로 초당 몇개의 instruction을 수행했는가, program 을 얼마나 수행했는가를 의미합니다.
Turnaround time : 소요시간
process 의 수행을 요청하고 해당 process가 끝날 때까지의 시간.
Response Time : 응답시간
process가 arrive하고 실행되기까지의 시간
Fairness : 형평성
process간의 CPU 를 할당받은 시간이 얼마나 차이나는지.
Scheduling Algorithms
FCFS (First Come First Served)
scheduling 의 가장 단순한 형태로 간단히 말해서 먼저 들어온 process를 먼저 처리해주는 scheduling 방식입니다.
이런 작동방식 덕분에 FCFS scheduling 할 때 ready queue 는 FIFO queue로 쉽게 구현하여 새로운 process가 들어오면 PCB 가 linkedlist 방식으로 이어지게 됩니다.
그러나 평균적인 waiting time이 길다는 단점이 있습니다.
아래의 예에서 보자면 time 0 에서 3개의 process가 P1, P2, P3 순서로 들어온다고 가정하면 각각의 turnaround time은 P1은 24ms, P2 27ms, P3 30ms 로 P2, P3는 적은 CPU실행시간을 가지고 있음에도 불구하고 turnaround time이 굉장히 긴 것을 확인할 수 있습니다.
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |

convey effect
위의 문제를 convoy effect라고도 합니다.
간단히 얘기하자면 CPU 수행시간이 긴 process가 앞에 있다면 그 뒤에 기다리고 있는 다른 process들의 waiting time이 굉장히 길어지는 현상을 뜻합니다.
SJF (Shortest Job First)
FCFS의 문제를 해결하기 위해 나온 개념으로 제목 그대로 실행시간이 짧은 process부터 실행시켜주는 scheduling 방식입니다.
| Process | Burst Time |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |

SJF는 짧은 일을 먼저 처리해주는 방식으로 turnaround time 이나 waiting time를 최소로 소모한다는 장점이 있습니다.
사실상 SJF 방식은 optimal 한 방식이지만 이는 실제 모든 process들의 CPU 소모 시간을 미리 알고 있다는 가정 하에 완벽하게 구현될 수 있는 방식입니다.
그래서 SJF는 process 의 CPU time을 특정 공식으로 대략적으로 예측하여 구현하곤 합니다.
대표적으로는 exponential average 방식으로 process가 이전에 얼만큼의 CPU 를 사용하였는지 보고 예측하는 방식이 있습니다.
\[\tau_{n+1} = \alpha t_n + (1-\alpha)\tau_n\]SRTF (Shortest remaining time first)
위의 SJF방식에는 모든 process의 arrival time이 거의 차이가 나지 않는다는 가정 하에 작동하는 방식이었습니다.
실제로는 arrival time이 다를 것이고, 그에 따라 SJF는 process 가 들어온 시점에서 다시 remaining time 들을 비교하여 실행할 process를 결정하는 SRTF방식을 따릅니다.
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |

Priority
사실 SJF 방식은 “실행시간” 을 기준으로 낮은 CPU 실행시간을 가진 process가 높은 우선순위를 가지도록 하는 priority scheduling의 방식 중 하나입니다.
Priority scheduling 방식은 특정 metric에 의해 각 process의 우선순위를 결정한 다음 그대로 process를 실행시키는 메커니즘을 가지고 있습니다. 그리고 이 우선순위는 process의 측정가능한 변수들인 시간제한, 메모리요구량, IO request 비율 등등 다양한 정보를 종합적으로 사용하여 판단합니다.
| Process | Priority | Burst Time |
|---|---|---|
| P1 | 3 | 10 |
| P2 | 1 | 1 |
| P3 | 4 | 2 |
| P4 | 5 | 1 |
| P5 | 2 | 5 |

하지만 이런 priority scheduling은 starvation의 문제가 있습니다. 낮은 우선순위를 가진 process는 높은 순위의 process가 끝나지 않는 이상 절대 실행될 수 없어 starvation이 일어납니다.
이를 해결하기 위해서 aging방식을 도입하여 시간이 지남에 따라 실행을 못한 process는 우선순위가 점차 올라가도록 하여 starvation 문제를 해결할 수 있습니다.
RR (Round Robin)
Round Robin scheduling 방식은 기본적으로 FCFS 방식과 비슷하지만 premption이 추가된 방식이라 볼 수 있습니다.
RR 에서 scheduler은 작은 시간 단위인 time slice를 정해두어 한 process가 time slice만큼 CPU 를 사용하면 그 다음 ready queue에 있는 process가 실행되는 방식입니다.
아래는 RR방식으로 time slice를 4ms 로 설정했을 때의 시나리오입니다.
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |

RR방식의 효율은 time slice의 크기에 따라 많이 달라집니다. 너무 짧으면 context switching이 많이 일어나서 process를 교체하는데 걸리는 시간이 더 커져 효율이 안좋아지고, 그렇다고 time slice가 커지면 FCFS 방식과 차이가 없어집니다.
그래서 적용하는 방식으로는 rule of thumb 라고 time slice가 80% 의 process 들의 CPU 실행시간보다 길게 하여 적절한 time slice를 찾을 수 있습니다.
Priority Scheduling with RR
현대 운영체제에서 기본적으로 사용하는 방식입니다.
기본적으로 priority scheduling방식을 따르지만 같은 priority를 가진 process들 끼리는 RR방식을 채용하여 실행시킵니다.
아래에서 볼 수 있듯이 (P2, P3) (P1, P5) 들은 같은 priority를 가지므로 2ms의 time slice 로 번갈아가며 실행되는걸 볼 수 있습니다.
| Process | Priority | Burst Time |
|---|---|---|
| P1 | 3 | 4 |
| P2 | 2 | 5 |
| P3 | 2 | 8 |
| P4 | 1 | 7 |
| P5 | 3 | 3 |

MLQ (Multi-level Queue)
priority방식과 RR 방식을 이용해서 모든 process들은 하나의 ready queue에서 scheduler에게 채택되기 전까지 대기합니다. 그리고 context switching 이 일어날때 적합한 process를 찾기 위해서 ready queue 를 찾으면 $O(n)$ 의 시간복잡도를 가지고 찾게 됩니다.
이를 좀 더 효율적으로 하기 위해 priority마다 다른 queue 를 관리하여 다음으로 실행될 process를 빠르게 찾을 수 있게 하는 방식을 Multi-level Queue방식이라 합니다.
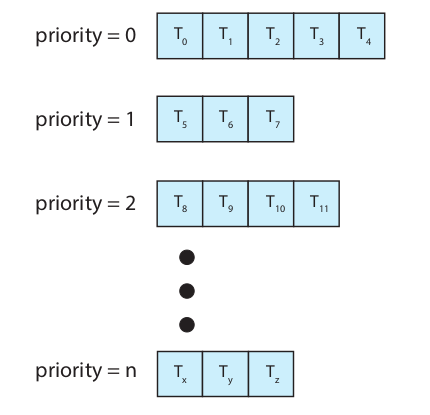
이 Multilevel Queue방식을 사용하면 각 process 마다 priority를 따지지 않고도 골라낼 수 있고, priority마다 또 다른 scheduling 방식을 적용하여 효율성을 증대시킬 수 있다는 장점이 있습니다.
하지만 이런 다단계 큐는 한번 process가 들어가게 되면 다른 queue로 이동하기 어려워 유연하지 못하다는 단점이 있습니다.
MLFQ (Multi-level Feedback Queue)
위의 문제를 해결하기 위해 feedback 방식을 더한 MLFQ 방식이 등장하게 됩니다.
기본적으로 multilevel 한 queue를 가지고 priority를 관리하고, level마다 다른 scheduling scheme이 있습니다.
아래의 그림을 예로 설명해보겠습니다.
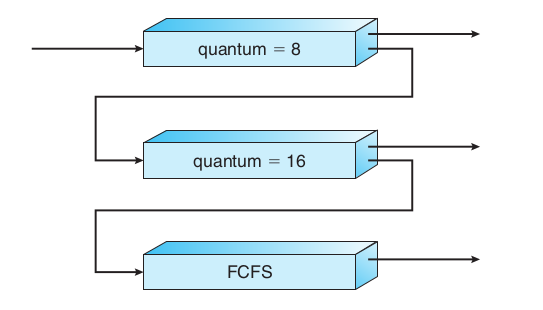
일단 process를 모두 제일 위의 queue에 넣게 됩니다. 맨 위의 queue에 담아진 process들은 time slice를 8ms 만큼 받아 실행하게 됩니다. 만약 한 process 가 여기서 time slice를 모두 채워 switching이 되었다면 아래의 queue로 이동하게 되고, 다 못 채웠다면 해당 queue 에 남게 됩니다.
그 아래의 queue는 두배의 time slice 를 가지고 RR방식으로 돌아가게 됩니다.
그리고 최종적으로 가장 밑에 있는 (가장 우선순위가 낮은) queue 는 FCFS방식으로 돌아갑니다.
그렇다면 우선순위는 왜 time slice를 채운 여부에 따라 달라지게 되는걸까요?
time slice를 다 채운다는 건 IO request를 많이 하지 않는, CPU burst time 이 큰 process라는 걸 내포합니다. 그래서 해당 process는 user interactive하지 않기 때문에, background 에서 돌아가는게 더 효율적이라고 생각되어 제일 후순위로 scheduling 되도록 하기 위해 queue를 아래로 이동하게 되는 것입니다.
Questions
-
CPU scheduling이란?
제한된 컴퓨팅 자원인 CPU를 어떤 process가 이용할 것인지 결정하는 것
- CPU scheduling이 발생하는 시점은?
- running → waiting (IO request)
- running → ready (Interrupt)
- waiting →ready (IO execution done)
- terminated
-
preemptive scheduling 과 nonpreemptive scheduling 방식의 차이?
CPU 를 할당받아 실행중인 process로 부터 CPU 의 실행권한을 빼앗을 수 있는지의 차이
-
사실상 활용 문제로 많이 물어볼 듯함
문제를 주고 어떤 방식으로 풀어나갈 건지 물어볼 때 사용하기 좋은 기법들을 소개했습니다.
-
process scheduling 방식들에 대해 얘기해 보세요
-
Aging 은 무엇입니까?
resource scheduling 할 때 starvation을 방지하기 위해 사용되는 기술로
process 의 기다린 시간에 따라 priority를 변경시키는 기법
참조문헌
Operating System Concepts 10th edition
양햄찌님 블로그 :https://jhnyang.tistory.com/notice/31