Cache
Cache란?
캐시는 데이터나 값을 미리 복사해놓은 임시저장소입니다.
Cache 를 쓰는 이유?
1. 메모리 계층구조
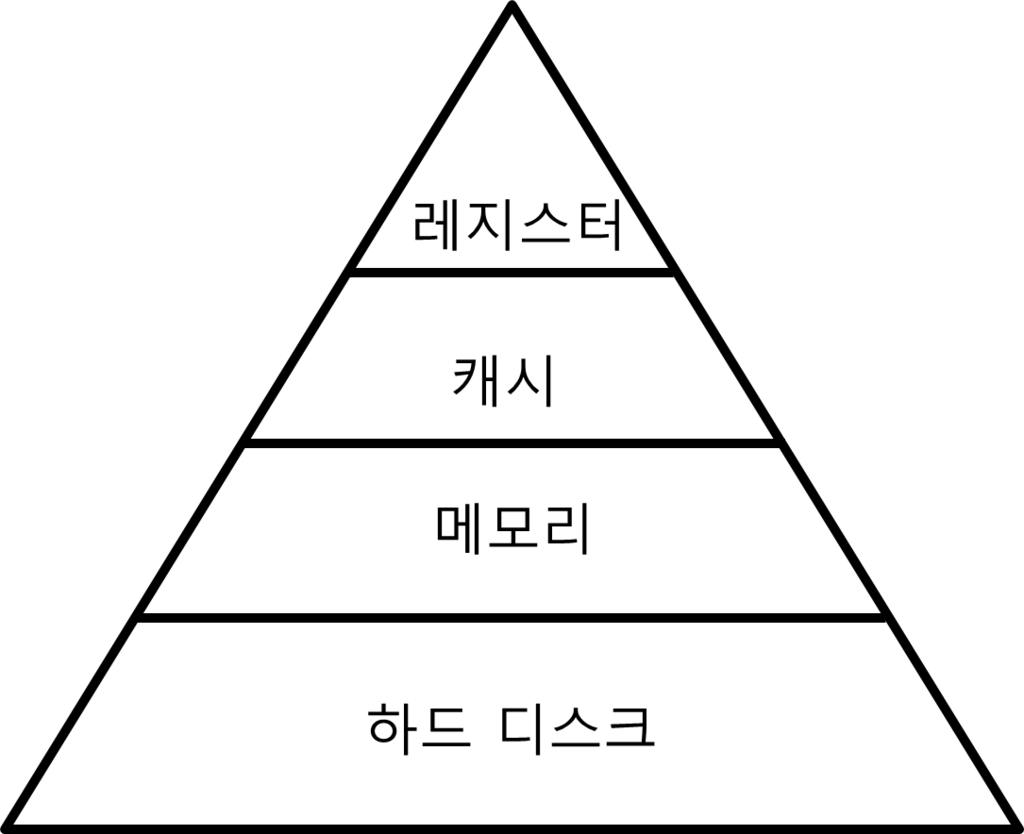
- 컴퓨터 내부의 메모리는 성능과 기능에 따라 레지스터 → 캐시 → 메모리 → 하드디스크 로 구분이 됩니다.
- 위에서부터 해당 메모리를 구성하는 하드웨어의 가격이 비싸서, 적은 용량의 비싼 하드웨어를 효율적으로 사용하기 위해 캐싱을 이용합니다.
2. 파레토의 법칙 (20-80 법칙)
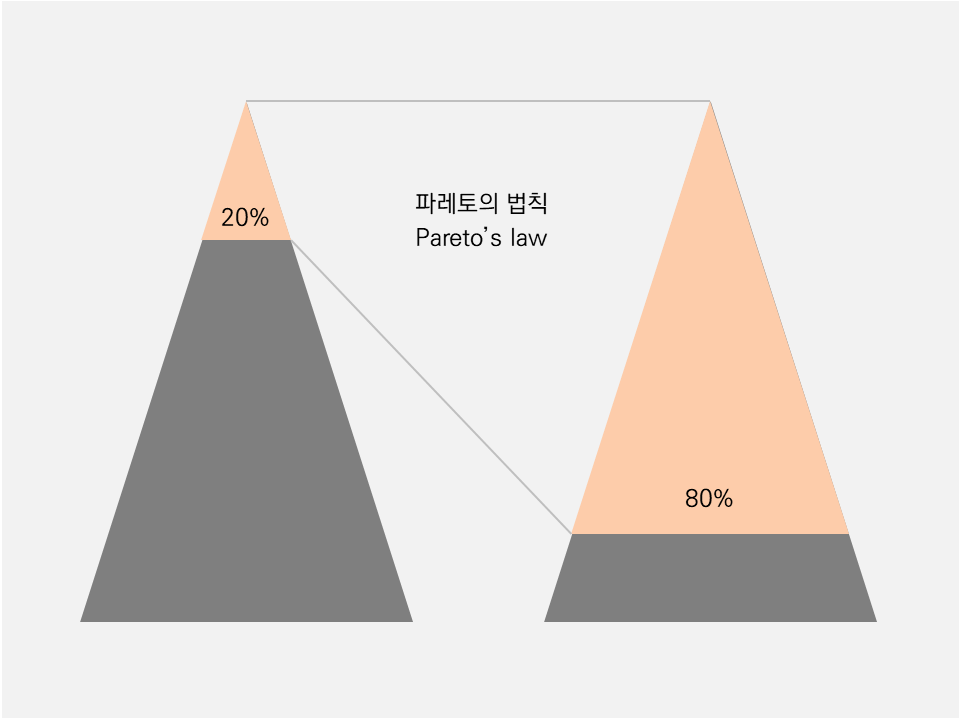
많은 사회현상을 분석할 때에도 쓰이는 법칙으로 캐싱 환경에서 해석하자면, 많이 쓰이는 상위 20%의 데이터들이 시스템 전체적으로 쓰이는 데이터의 80% 를 차지한다라고 할 수 있습니다.
cache가 유효한 이유?
데이터 지역성의 원리
-
시간 지역성
참조되는 데이터가 한번 접근되었을 경우 가까운 미래에 또다시 참조될 확률이 높다는 특징을 가지고 있습니다.
-
공간지역성
참조되는 데이터의 주변공간에 다시 접근할 확률이 높은 경향을 말합니다.
for(i=0; i<10; i++){
arr[i] = i;
}
위의 loop에서는 i가 time locality를 잘 표현하고, arr의 배열이 참조되는 것이 space locality를 잘 나타내 줍니다.
작동방식
- 원본데이터와는 별개로 자주 쓰이는 데이터들을 복사해둘 캐시공간을 마련한다. 해당 공간은 기존의 데이터 저장소보다 빠른 시간으로 접근이 가능한 공간으로 설정합니다.
- 데이터의 요청으 들어오면 원본 데이터가 담긴 저장소를 참조하기 전에 캐시 메모리를 탐색하여 해당 데이터가 있는지 확인합니다.
-
cache hit
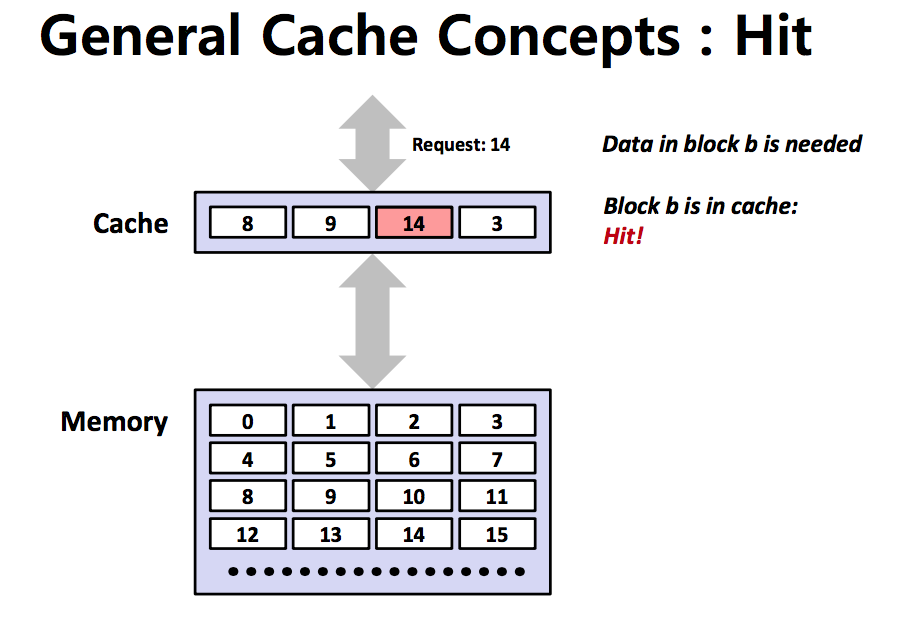
만약 있으면 캐시에서 해당 데이터를 불러옵니다.
-
cache miss
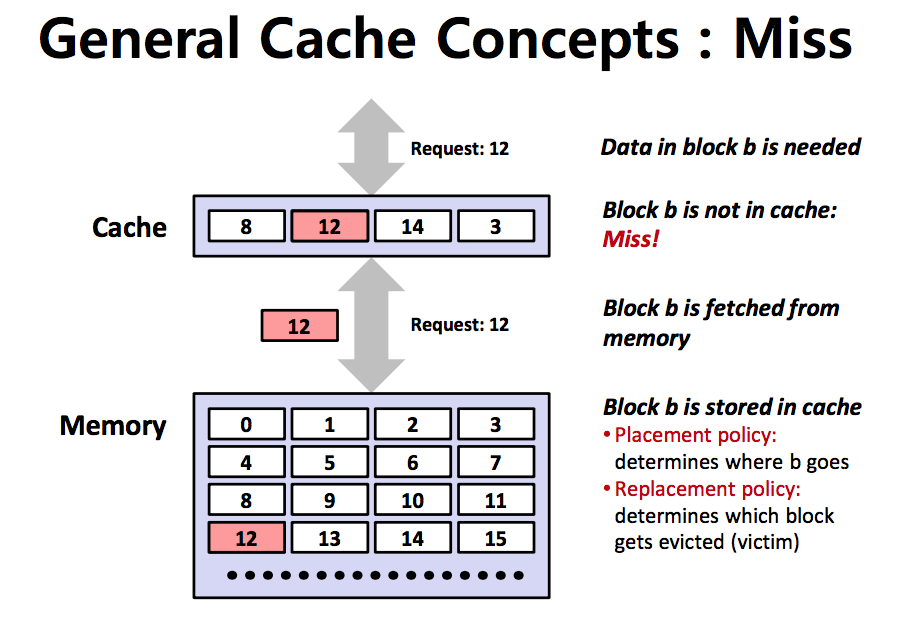
만약 없으면 원본 데이터가 있는 저장소에 접근하여 데이터를 가져오고, cache에도 해당 데이터를 복사하거나 갱신합니다.
-
- cache 메모리는 공간이 적으므로 공간이 모자라게 되면 replacement policy에 따라 cache안에 있는 데이터를 삭제하고 새로운 데이터를 넣습니다.
- 캐시의 성능은 hit latency, miss latency에 의해 결정됩니다. 요청한 데이터가 캐시에 존재할때 걸리는 시간을 hit latency, 없을 때 걸리는 시간을 miss latency라고 합니다.
- 캐시의 성능을 높이기 위해서는 캐시의 크기를 줄여 hit latency를 줄이거나, 캐시의 크기를 늘려 miss 비율을 줄이거나, 아예 하드웨어적으로 더 빠른 메모리를 캐시로 사용하여 레이턴시를 줄이는 방법이 있습니다.
구현
32bit으로 주소를 표현한다고 가정하에 주어진 참조할 주소값에 따른 cache indexing 에 대해 간단히 알아봅시다.
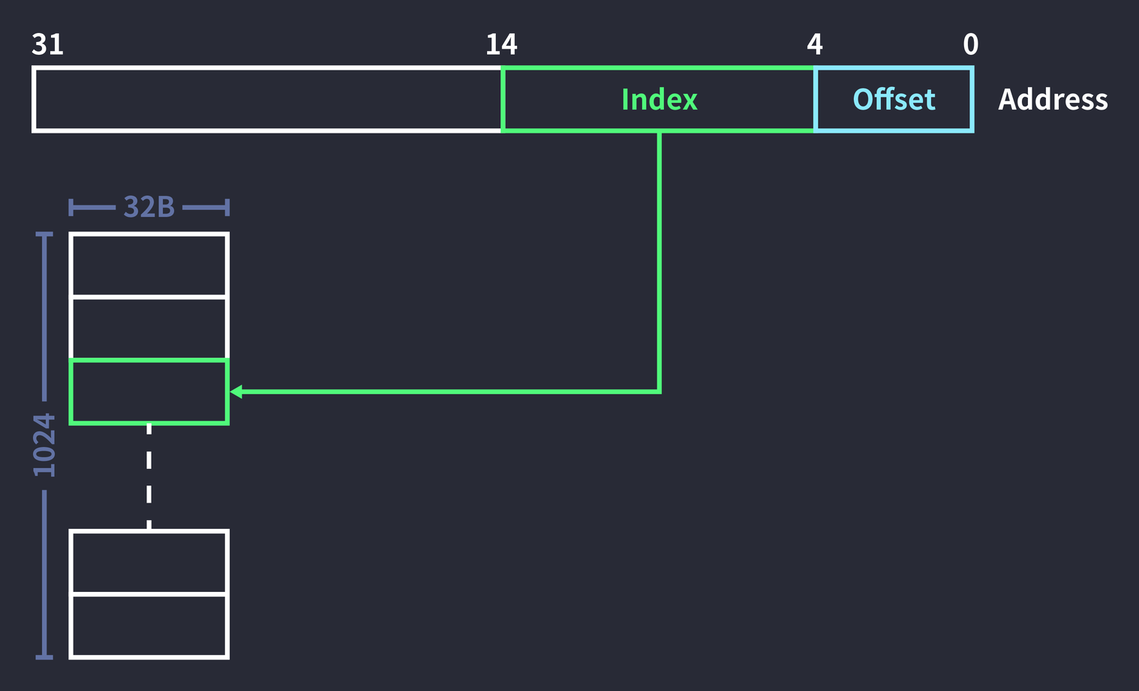
-
Index
주소값이 주어질 때 이 주소값에 해당하는 데이터가 들어있을 수 있는 캐시의 주소를 담는 자리입니다.
만약 캐시의 블록 수가 1024개면 10bit 로 해당 캐시의 주소값을 다 표현할 수 있어, 주소값을 줄 때 index 값을 10자리를 부여합니다.
-
Offset
Index에서 캐시의 entry를 찾아줬다면, offset은 해당 entry안에서 어느 위치를 살펴볼지를 표시한 자리입니다.
캐시의 한 블록당 32byte의 정보를 담고 있다면 offset는 5자리로 모두 표현이 가능합니다.
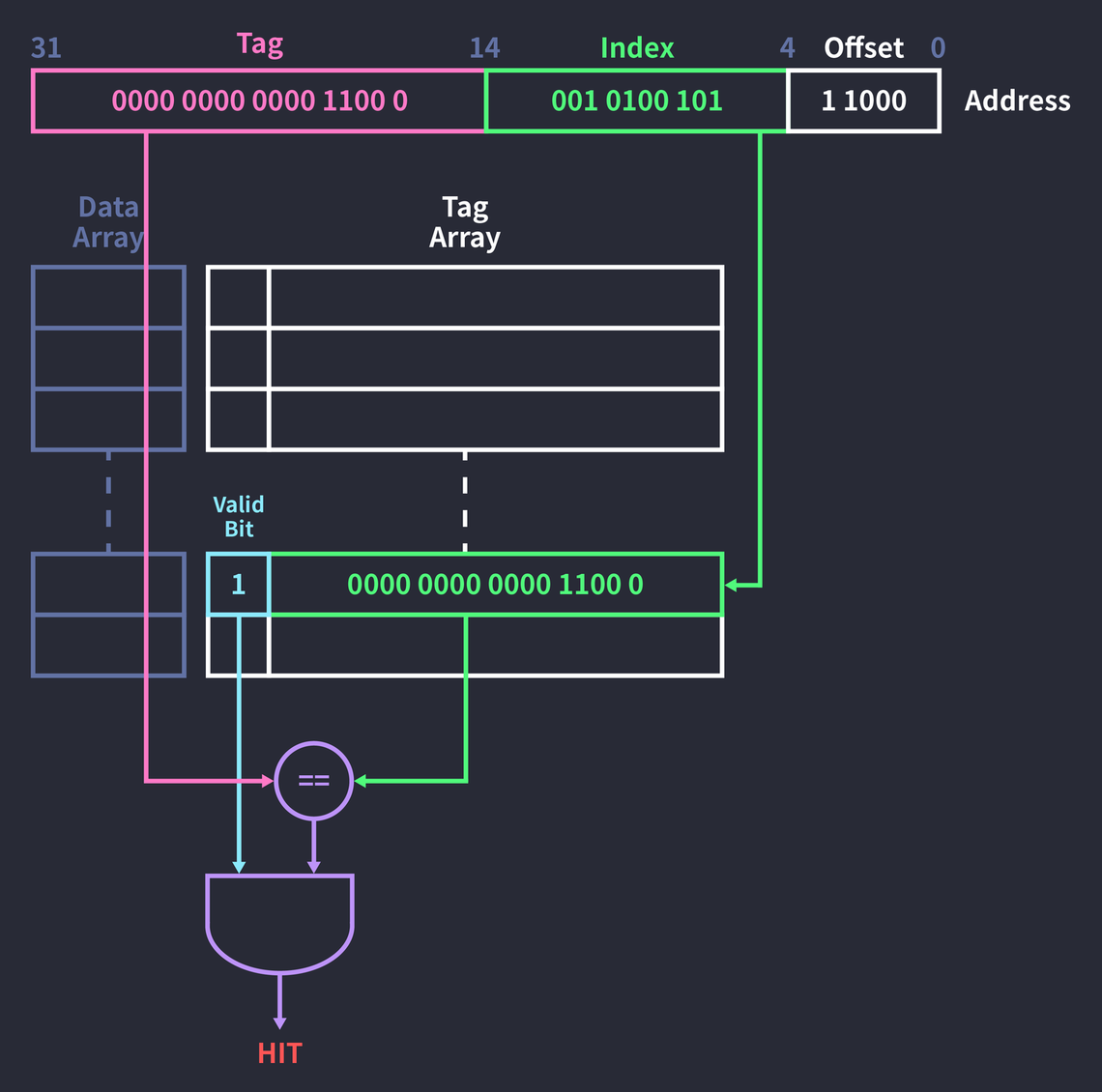
-
Tag
cache hit을 판단할 때 사용하는 자리로, 캐시 entry에 들어있는 정보가 해당 address 가 요청한 데이터가 맞는지 확인하는 정보입니다.
위의 그림처럼 32비트 주소 0x000c14B8에 접근한다고 가정해봅시다.
(0000 0000 0000 1100 0001 0100 1011 1000)
[tag matching]
- 먼저 index에 해당하는 태그 배열의 필드에 접근합니다.
- 이어서 해당 태그 필드의 valid bit을 확인합니다
- valid bit가 1이라면, 태그 필드와 주소의 태그가 같은지 AND연산하여 결과를 확인합니다
- 결과가 1로 나오면 cache hit 하였다고 판단하고 data array에서 데이터를 가져옵니다.
- 만약 1이 안나오면 miss 가 발생하였다고 판단하고 해당 cache entry를 교체정책에 따라 교체해줍니다.
Direct Mapping
위와 같이 하나의 Index 에 해당하는 cache entry는 하나만 있는 캐시 구현방법을 direct mapping이라고 합니다.
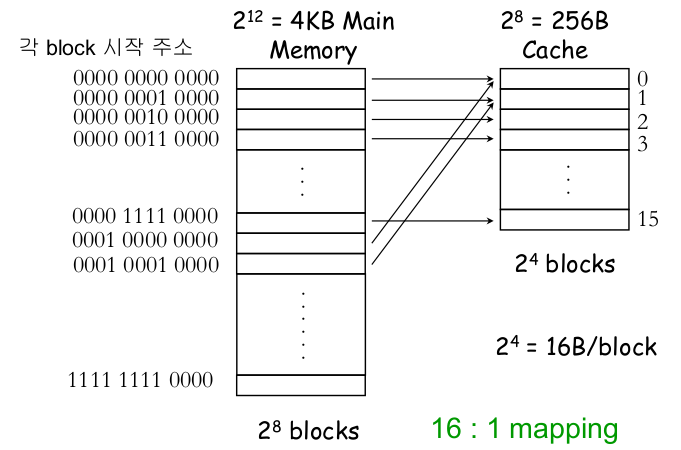
Set-associative Mapping
서로 다른 두 주소가 같은 인덱스를 가지면 충돌이 발생하고, 교체 정책에 따라 블록을 교체하게 됩니다.
하지만, 하나의 자리에서 계속 충돌이 발생하는 경우에 충돌마다 캐시 내용을 바꾸면 계속 miss가 발생하는 핑퐁문제가 발생합니다.
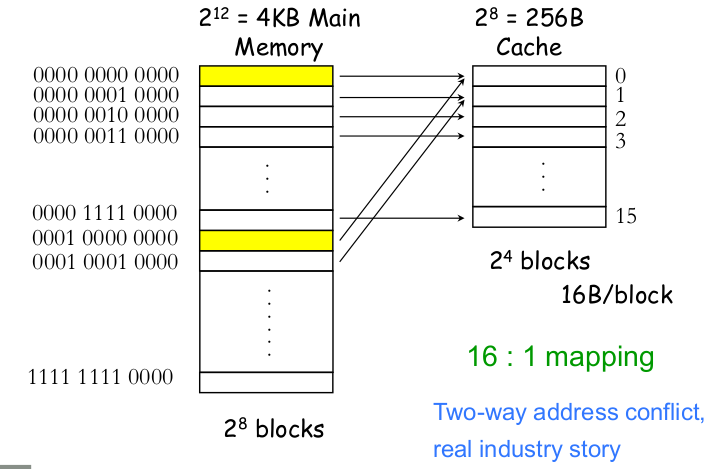
이 문제는 한 index가 가르키는 캐시블록이 여러개가 되도록 하여 해결할 수 있습니다.
아래그림은 2-way set associative 캐시입니다.
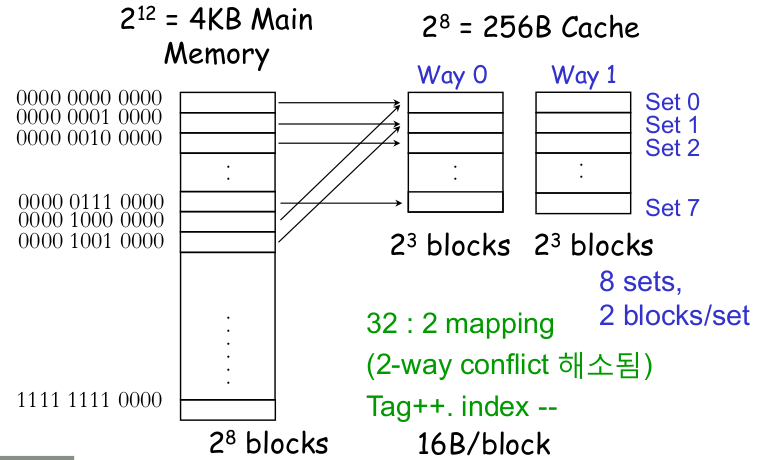
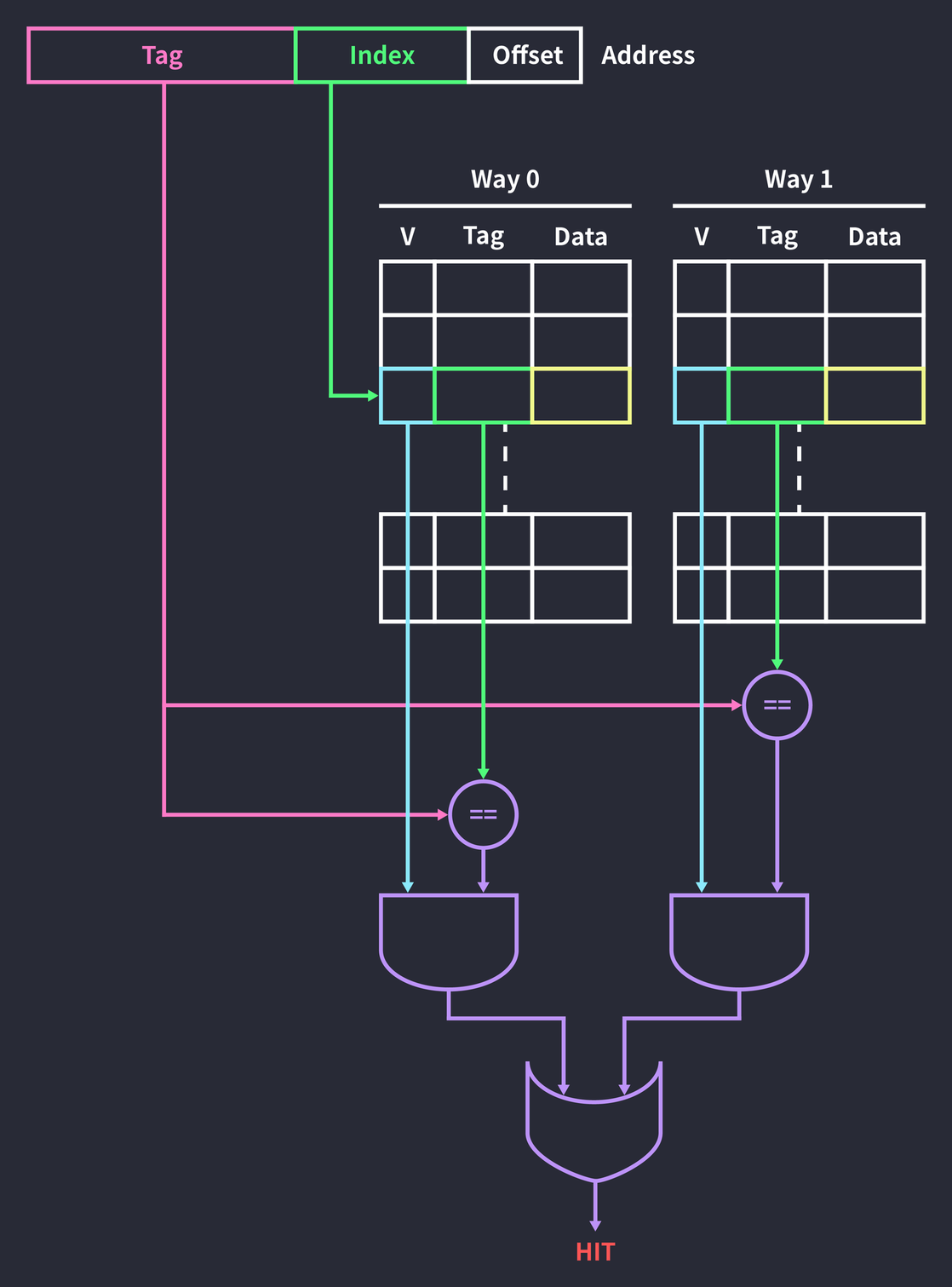
주소의 인덱스를 통해 블록에 접근하는 것은 direct mapping 캐시와 동일하지만 2개의 way가 있기 때문에 데이터가 캐싱되어 있는지 확인하려면 블록 2개 다 확인해봐야 합니다.
이를 위해 마지막에 AND 결과와 AND결과를 OR 연산하여 hit 되었는지 판단합니다.
set associative 방식을 사용하면 miss rate를 줄일 수 있어 cache의 성능을 늘릴 수 있지만, 하드웨어 구조를 복잡하게 만들고, hit time이 늘어나는 단점이 있습니다.
데이터 업데이트 정책
cache hit이 일어나 해당 데이터를 불러와 수정이 일어날 경우 그에 해당하는 메모리 안의 값도 업데이트 시켜줘야 합니다. 어떤 update 정책을 사용하느냐에 따라 캐시의 성능이 달라집니다.
Write Through
cache가 업데이트 될 때 그에 해당하는 메모리 안의 값도 update 시켜주는 방법입니다.
Write Back
cache에 수정이 일어났다는 dirty bit만 업데이트 시켜주고, 해당 블록이 replace될 때, dirty bit을 확인하여 메모리에 업데이트하는 방식입니다.
cache 가 활용되는 시스템
-
CPU 의 캐시메모리
CPU 의 속도에 비해 메인메모리에서 정보를 주고받는 일은 오래걸려서 CPU time 에 맞는
- 하드디스크
- 데이터베이스
- CDN (Content Delivery Network)
- 웹 캐시
- 네트워크를 통해 데이터를 가져오는 것은 하드디스크보다도 느릴 때가 있습니다.
- 웹 브라우저는 웹 페이지에 접속할 때 로컬 메모리에 html, css, javascript 파일을
- 브라우저 캐시
- Redis
- NoSQL 의 일종으로 웹 서비스에서 캐싱을 위해 많이들 쓴다
- dictionary 느낌의 저장소
- EHcache
- 자바진영에서 제일 많이 쓰이는 캐시
Questions
- cache에 대해 설명해보세요
- 캐시의 정의
- 캐시의 지역성(캐시가 유효한 이유) → time/space locality
- 캐시의 작동방식 → cache hit / miss 때 일어나는 일
- 캐시의 구현방법 → direct mapping / set associative mapping
- 캐시의 블록이 write 되었을 때 → write through , write back 방식
- 캐시의 정의
- cache를 구현해보세요 (라이브 코딩)
- CPU 의 메모리 I/O 도중 생기는 병목현상 해결방법 ⇒ cache 로 답변하는게 적절해보임
- 다른 방법으로는… 메모리 I/O 자체를 줄이기?
- thrashing 을 고려하여 프로세스마다 주어지는 최소 frame 을 적절히 부여하여 page fault 비율 줄이기
- page size 를 조절하여 page fault 비율과 page in-out 자체 시간의 trade-off 되는 특징들을 잘 조절
- replacement algorithm을 시스템에 맞게 선택
- 다른 방법으로는… 메모리 I/O 자체를 줄이기?
Ready-For-Tech-Interview/Cache.md at master · WooVictory/Ready-For-Tech-Interview