SQL이란?
SQL (“에스큐엘” 또는 “시퀄”)은 Structured Query Language 의 약자로, (NoSQL 계열을 제외한) 데이터베이스를 관리하기 위해 만들어진 프로그래밍 언어이다. 이때 “Structured”는 데이터가 표로 정리되어 구조화되어있다는 뜻이고, “Query”는 사용자가 데이터베이스에게 ‘CRUD(생성(Create), 조회(Read), 갱신(Update), 삭제(Delete))’ 요청을 할 수 있다는 뜻이다.
SQL은 관계형 데이터베이스를 다루는데 쓰이는 ‘표준화된’ 언어이다. 대부분의 회사들이 SQL 형태의 인터페이스를 제공하는 서비스를 사용해 데이터를 관리한다. 따라서, 개발자라면 분야를 막론하고 기본적인 SQL문을 익혀놓는 것이 좋다.
(참고 : ANSI SQL 이라는 표준 SQL 구문이 있으나, 벤더마다 제공하는 SQL 문법은 조금씩 상이하다)
SQL은 크게 데이터 정의어(DDL), 데이터 조작어(DML), 데이터 제어어(DCL) 로 나뉜다. 자세한 건 What is DB => DBMS의 필수 기능 참고.
용어 정리
테이블
- 관계형 데이터베이스에서는 여기에 특별한 제약을 추가해서 릴레이션(Relation)이라고 부른다.
- 아래 조건을 충족하는 테이블만이 릴레이션이 될 수 있기 때문에 모든 릴레이션은 테이블이지만, 모든 테이블이 릴레이션인건 아니다.
- 모든 값은 유일한 값을 가진다.
- 하나의 릴레이션에서 중복되는 행이 존재하면 안된다.
행
- 튜플/레코드
열
- 일반적으로 테이블의 속성을 의미하며 열을 구성하는 값들은 같은 도메인(Domain)으로 되어 있다.
- 이또한 관계형 데이터베이스에서는 속성(Attribute)이라는 이름으로 불린다.
Key
- 검색이나 정렬 시 Tuple을 구분할 수 있는 기준이 되는 Attribute.
Candidate Key
- 모든 릴레이션은 반드시 하나 이상의 후보 키를 가져야 한다.
- 릴레이션에 있는 모든 튜플에 대해서 아래 조건을 충족시켜야 한다.
- 유일성 : 테이블에서 각 레코드를 식별할 수 있도록 유일해야 한다.
- 최소성 : 유일성을 만족하는 한도 내에서 최소한의 컬럼 개수(하나 이상)로 구성돼야 한다.
- 한 테이블이 여러 개의 Candiadate Key를 가질 수 있다.
- Null 값을 허용한다.
Primary Key (기본키)
- 여러 개의 Candidate Key 중 단 하나를 골라 Primary Key로 사용한다.
- Candidate Key와 같이 유일성 & 최소성 조건을 만족하며, 더불어 개체 무결성 조건도 만족해야 한다.
- 개체 무결성 : 값의 유일성을 보장받아야 한다. (1) Null 값을 가질 수 없으며 (2) 속성에 동일한 값이 중복돼 나타날 수 없다.
Foreign Key
- 다른 테이블의 Primary Key를 참조하는 Attribute. (속성명은 달라도 된다)
Null값
- 데이터베이스에서 아직 알려지지 않았거나, 모르는 값으로서 “해당 없음” 등의 이유로 정보 부재를 나타내기 위해 사용하는, 이론적으로 아무것도 없는 특수한 데이터를 뜻한다.
참고) 온라인으로 SQL 쿼리 실행해볼 수 있는 사이트:
기본적으로 왼쪽 필드에 DDL, 오른쪽 필드에 DML 작성 후 [Run] 버튼 누르시면 됩니다.
또한 왼쪽 상단 메뉴에서 MYSQL 5.6 으로 맞춰주세요!
기본 SQL 문법 (1) Schema
데이터베이스 생성과 삭제
-
생성 후 사용
CREATE DATABASE userId; --- 데이터베이스 userId를 생성합니다. CREATE DATABASE IF NOT EXISTS userId; --- userId라는 데이터베이스가 존재하지 않는다면 생성합니다. USE userId; --- userId라는 데이터베이스에서 작업 시작합니다. -
생성된 데이터베이스 모두 나열
SHOW DATABASES;
-
삭제
DROP DATABASE userId; --- DROP은 DB 자체를 삭제, DELETE은 DB 내용을 삭제(초기화)한다고 생각하면 됩니다.
테이블 생성, 수정, 삭제
-
테이블 스키마 생성
CREATE TABLE Students ( sid int NOT NULL AUTO_INCREMENT, --- 속성이름-타입-제약조건 순서입니다. name char(10) NOT NULL DEFAULT '', age int unsigned, PRIMARY KEY (sid), --- 이렇게 하지 않고 sid 의 제약조건으로 PRIMARY KEY를 걸 수도 있습니다. --- FOREIGN KEY (cid) REFERENCES Course(cid) (Foreign key는 후에 자세히 서술) ); --- Students 라는 테이블(의 스키마)을 만듭니다. --- 필드는 sid, name, age 이고 PRIMARY KEY는 sid 이고, --- GpaTable이라는 테이블의 gpa 필드를 FOREIGN KEY로 참조합니다.
속성엔 다음 제약 조건을 걸 수 있다. 제약 조건을 거스르는 조작은 거부된다.
제약조건 설명 NOT NULL / NULL 해당 필드는 NULL 값을 저장할 수 없다 / 해당 필드는 NULL 값을 허용한다. UNIQUE 각 튜플의 해당 필드 값은 테이블에서 고유해야한다. PRIMARY KEY NOT NULL과 UNIQUE 제약 조건의 특징을 모두 가진다. FOREIGN KEY 해당 필드는 다른 테이블의 필드에 의존한다. DEFAULT 해당 필드의 기본값을 설정한다. AUTO_INCREMENT 시작값 1에서, 새로운 레코드가 추가될 때마다 1씩 증가한 값으로 저장한다. -
테이블 스키마 보기
DESCRIBE Students;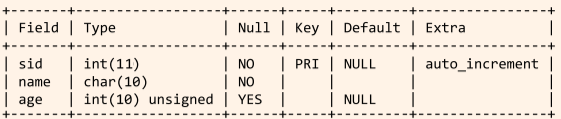
-
테이블 스키마 수정
ALTER TABLE Students ADD COLUMN department VARCHAR(20); --- Students 테이블에 department 라는 필드를 추가합니다.
-
테이블 삭제
DROP TABLE Students;
데이터(튜플) 삽입, 수정, 삭제
-
삽입
INSERT INTO Students VALUES (NULL, 'David', 23, 'Electronics'); --- 새로운 튜플을 Students 테이블에 삽입합니다. INSERT INTO Students (sid, name) VALUES (150, 'Kim'); --- 이 다음으로 삽입되는 튜플의 sid는 (따로 설정하지 않으면) 151 이 됩니다. --- 값을 넣지 않은 필드(age, dept)에는 디폴트값이 들어갑니다. -
테이블 내 데이터 보기
SELECT * FROM Students;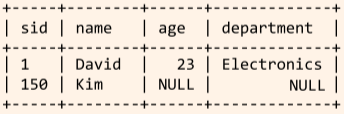
-
수정
UPDATE Students SET age = 20, department = 'Arts' WHERE name = 'Kim'; --- 이름이 Kim인 학생의 age, dept 필드 값을 변경합니다. -
삭제
DELETE FROM Students WHERE sid = 150; --- sid가 150인 튜플을 삭제합니다. DELETE FROM Students; --- 조건을 생략하면 모든 튜플이 삭제됩니다.
기본 SQL 문법 (2) Single-table Query
-
다음 데이터를 가정한다:
CREATE TABLE Students ( sid int NOT NULL AUTO_INCREMENT, name char(10) NOT NULL DEFAULT '', age int unsigned, gpa double NOT NULL DEFAULT '0.0', PRIMARY KEY (sid) --- FOREIGN KEY (gpa) REFERENCES GpaTable ); ALTER TABLE Students ADD COLUMN department VARCHAR(20); INSERT INTO Students VALUES (100, 'Fred', 23, 3.5, 'Computer Science'), (NULL, 'David', 23, 3.7, 'Electronics'), (NULL, 'John', 21, 3.3, 'Electronics'), (NULL, 'Jake', 24, 4.0, 'Computer Science'), (NULL, 'George', 22, 2.8, 'Computer Science');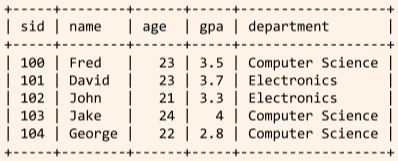
-
SELECT (SFW)
SQL 쿼리의 기본 형태는 “SFW query”이다.
간단하게SELECT는 조건에 맞는 속성을,WHERE는 조건에 맞는 튜플을 골라낸다고 생각하면 된다.SELECT name, department FROM Students; --- Students 테이블의 name, department 필드를 보여줍니다. --- WHERE 조건이 없으므로 모든 튜플이 대상입니다. SELECT * FROM Students WHERE age < 23; --- * 는 모든 필드를 보여줍니다. --- age 값이 23 이상인 튜플만 대상입니다.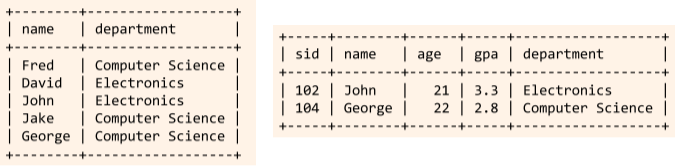
-
DISTINCT
SELECT DISTINCT department FROM Students; --- 중복을 제거한 department 값을 보여준다. SELECT DISTINCT department, name FROM Students; --- 중복을 제거한 department, name "쌍"의 값을 보여준다.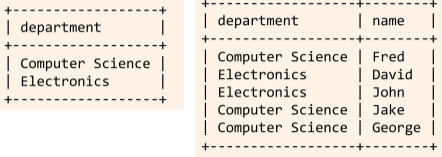
-
LIKE
SELECT name FROM Students WHERE name LIKE '_a%'; ---** _ 는 한 개의 char, % 는 0~n개의 char를 가진다는 뜻입니다. --- 따라서, David Jake 가 해당됩니다. -
연산자 사용
산술 연산자 논리 연산자 비교 연산자 비교 연산자2 + - / * and, or, not > < >= <= = != ^= <> between and, in, is null, like SELECT 11 / 4; --- 이런 수학적 연산도 가능합니다. 참고로, SELECT 11 DIV 4와 동일합니다. SELECT name FROM Students WHERE NOT (name LIKE '%e_' **OR** gpa >= 4.0); --- 이런 논리 연산도 가능합니다. SELECT * FROM Students WHERE sid IN (100, 103, 105); SELECT * FROM Students WHERE gpa BETWEEN 4.0 AND 4.5; --- 이런 비교 연산도 가능합니다. -
AS
SELECT sid AS '학번', name AS '이름' FROM Students; --- 필드를 별칭(alias)으로 보여줍니다.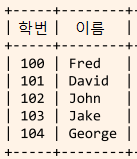
-
-
ORDER BY
SELECT name, age, gpa FROM Students ORDER BY age ASC, gpa DESC; --- 기준에 따라 정렬합니다. 콤마(,)로 여러 기준을 나열할 수 있습니다. --- 첫번째 기준 age 에서 동률인 항목이 두번째 기준 gpa 로 정렬됩니다. --- 기본은 오름차순이나, DESC 키워드로 내림차순으로 정렬할 수 있습니다. --- 문자열은 알파벳 순으로 정렬됩니다.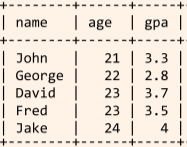
-
LIMIT
SELECT name, gpa FROM Students ORDER BY gpa DESC LIMIT 3; --- gpa 를 내림차순한 상태로 상위 3 개만 보여줍니다. --- LIMIT 0,3 => 0 순위부터 3개만 보여줍니다.
-
-
GROUP BY
특정 속성의 값이 같은 튜플들을 임시로 묶음 처리 해준다.
SELECT department FROM Students GROUP BY department; --- 같은 department 값을 가진 튜플끼리 임시로 묶여있다.
-
AGGREGATION
그룹핑은 다음 계산 함수들과 자주 함께 사용된다. 같이 묶인 튜플의 값끼리 처리된다.
| max / min | avg | count | sum | std | | — | — | — | — | — |
SELECT department, COUNT(*) AS '인원수', --- COUNT(gpa) 도 결과는 동일합니다. MAX(gpa) AS '최고학점', SUM(gpa) AS '총합', AVG(gpa) AS '평균' FROM Students GROUP BY department;
-
HAVING
언제나
GROUP BY와 함께 사용되며, 조건에 맞는 ‘그룹’을 추출한다.📌
WHERE와HAVING의 차이점?WHERE는 개별 튜플을 필터링하는 데 사용되지만,HAVING은 그룹화 또는 집계가 발생한 후 그룹을 필터링하는 데 사용된다. 따라서 그룹핑 후에 조건을 줄 땐 반드시HAVING을 써야 한다.SELECT department, AVG(age) FROM Students GROUP BY department HAVING COUNT(*) > 2; --- department 값이 같은 튜플끼리 묶은 후, 포함된 튜플의 개수가 2 초과인 그룹만 고릅니다.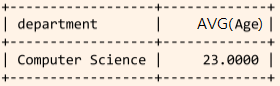
-
정리하자면…
SELECT 속성
FROM 테이블
WHERE 테이블조건
GROUP BY 속성
HAVING 그룹조건
ORDER BY 속성
실행 순서는 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY 이다.